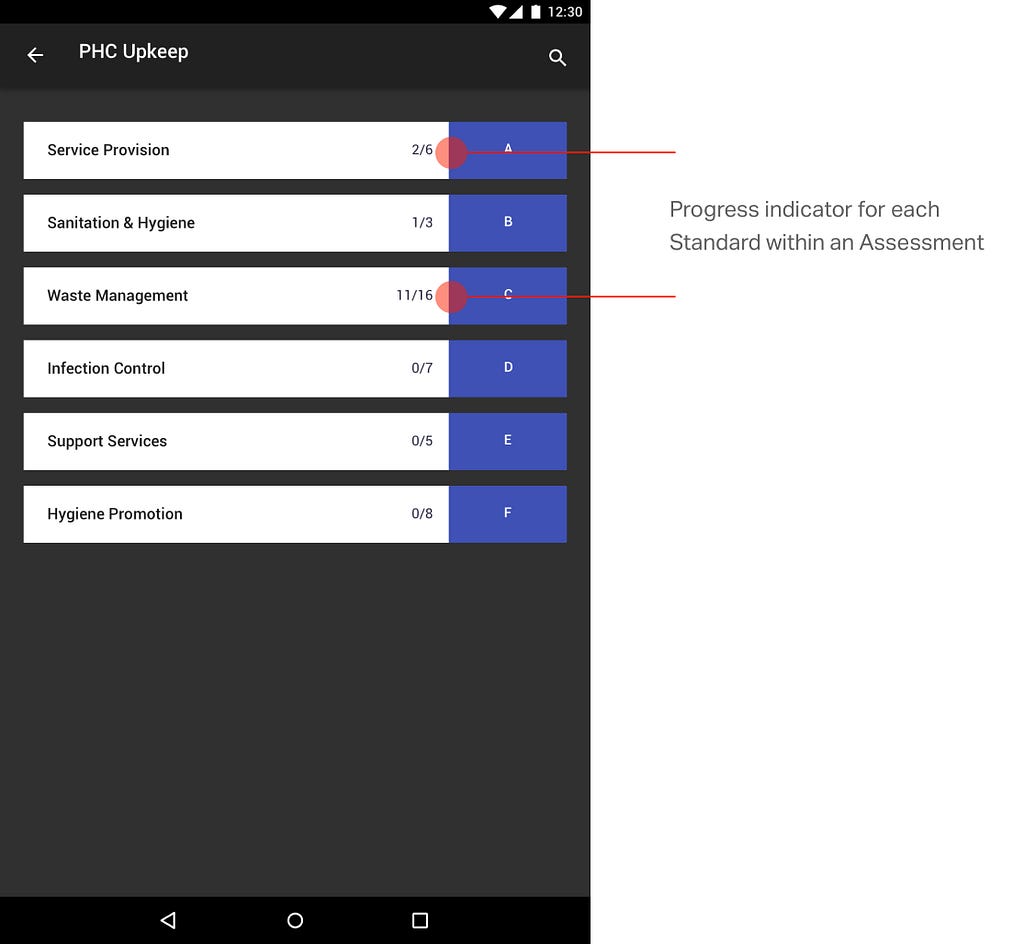
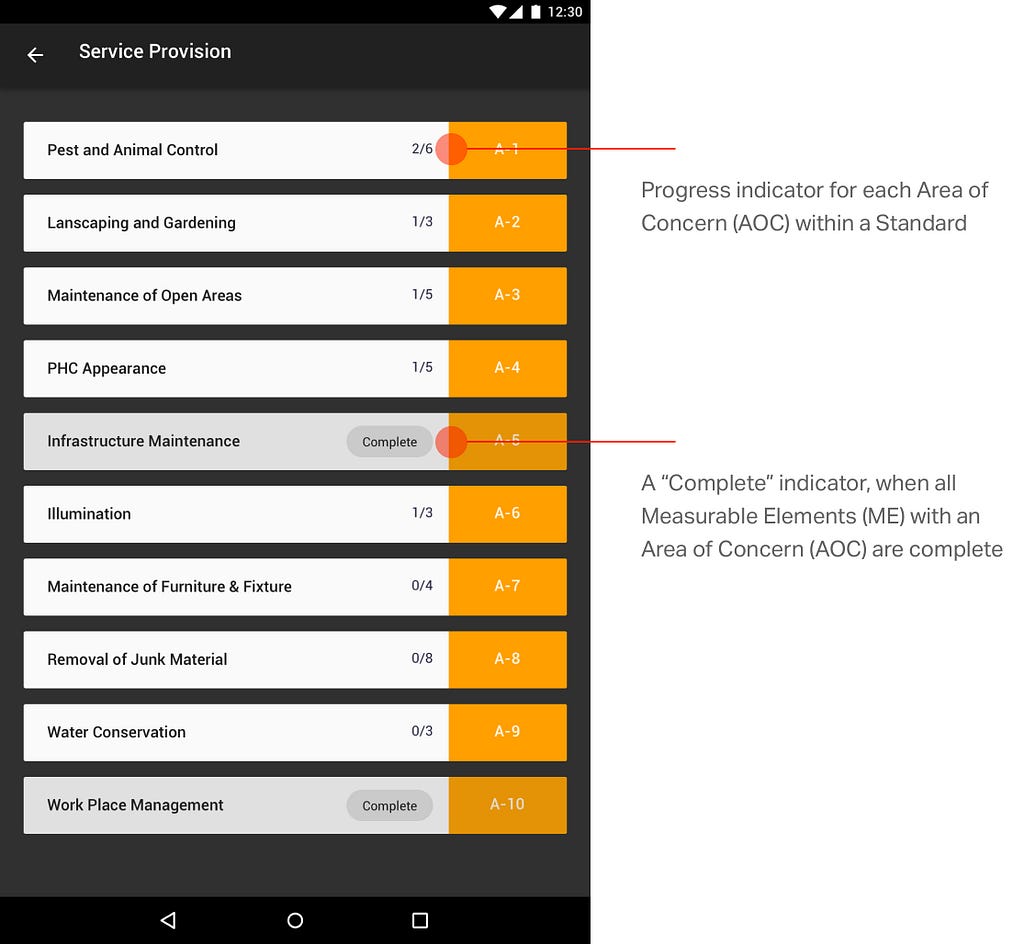
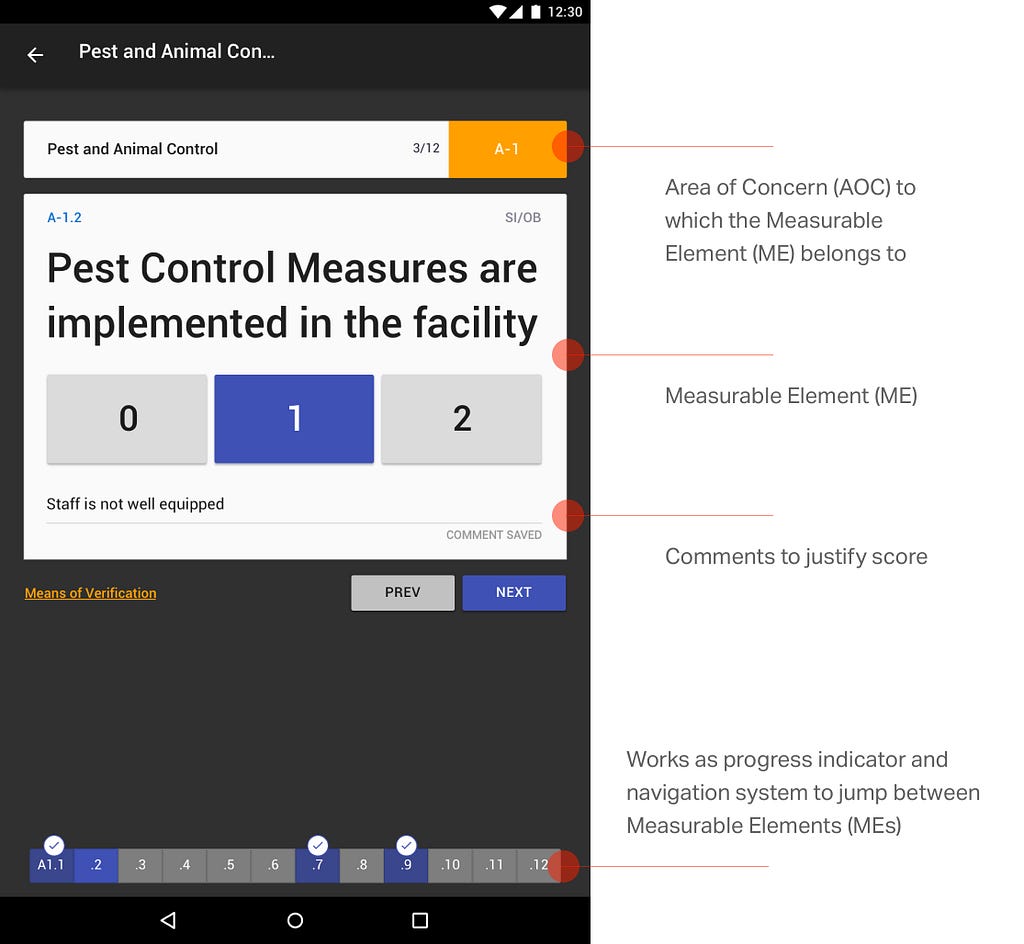
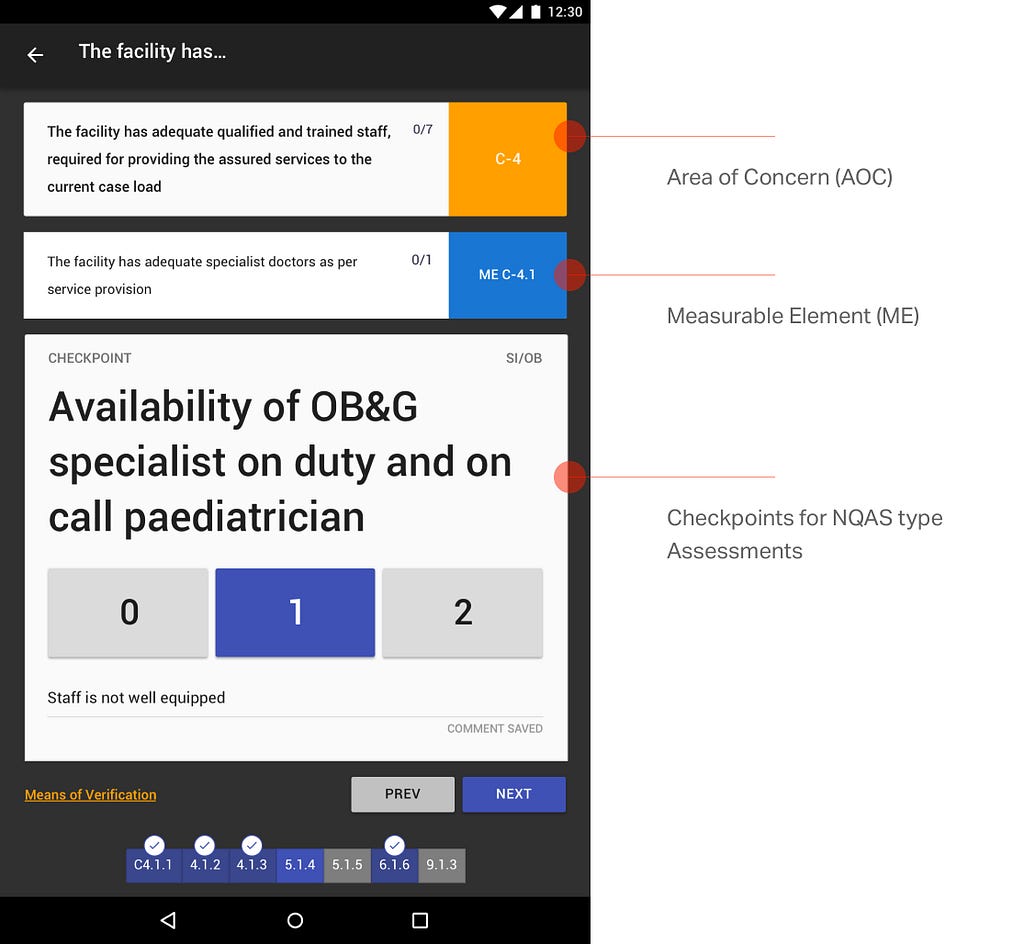
<![CDATA[nilenso blog]]>2024-09-13T14:16:12+00:00http://blog.nilenso.com/Octopress<![CDATA[A caution against ephemeralization]]>2024-09-13T00:00:00+00:00http://blog.nilenso.com/blog/2024/09/13/a-caution-against-ephemeralizationThese days I derive little joy from my possessions of necessity. Over the last couple of decades, knowledge workers have traded the engagement of our senses for an upgrade in flexibility. I shall elaborate.
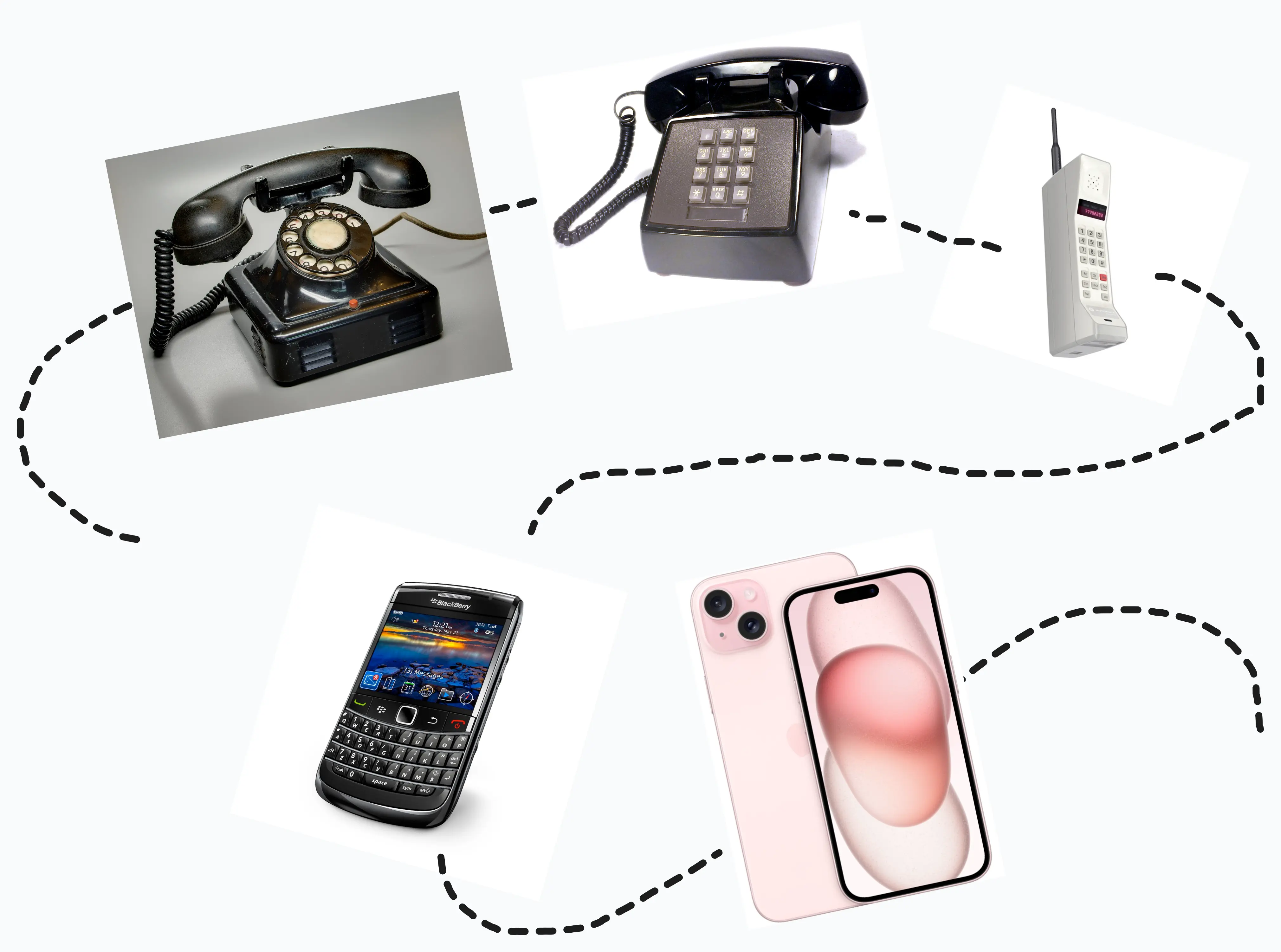
Let’s take a phone. Here’s a rough chronology.
Notice the gradual loss of visual, tactile and sensory stimuli (henceforth dimensionality) in the experience of making a phone call. A smartphone is a relatively easy example to pick on. But this is true of many other possessions and their “modernised” counterparts.
High dimensionality article
Lower dimensionality modern “evolution”
Buttons, Gauges, Dials, Sliders
Touchscreens, Capacitive Buttons
Physical Books
Audiobooks, eBooks, Websites
Pen and Paper
Text file, Note-taking apps
Typewriters
Touchscreen keyboards
Paper Money
Digital Payments/UPI
Fish Market
Licious
Mango
Maaza, Slice, Tropicana
Glass bottle coke
Plastic bottle coke
Morning jog
Treadmills
Sports, Board Games
Video Games
Theater
Cinema
Fireplace
Indoor Heaters
Working in an office
Remote work
Live Music, Record Players
mp3s, Spotify
I have seen a desire for higher-dimensionality articles dismissed as paranoid technophobia or an irrational longing for the past. There have also been arguments in favour of intentionally moving to low dimensionality—here’s Marc Andreesen quoting futurist Buckminster Fuller, on the topic of ephemeralization:
Technology lets you do more and more with less and less until eventually, you can do everything with nothing.
Actually, the above is likely a misquotation. The only occurrence of this quote in my research is Marc’s website. I could not find any such passage in Fuller’s book where he introduces and discusses the term ephemeralization. But I digress.
My point is that we must consider the costs of ephemeralization. I believe that a prerequisite for a well-examined life is to, as much as possible, be present with the raw sensation of experience. That’s why it’s important to design things that engage with more channels of sensory reception, especially in ways that ground the user to the present moment. It’s a subtle human need. This low dimensionality of modern technology is why there’s some innate resistance and a lack of joy in their use (excluding some short-term dopamine bursts).
Yet, the considerations of scalability, economic optimisation and extreme convenience will always win over this subtle, unmeasurable and “unjustifiable” characteristic of “low engagement of human sensory experience”. And I wouldn’t say it’s a good idea to pick the left column in my table every time. I am not anti-technology.
But consider the things in the left column anyway. There’s a huge loss in the dimensionality of articles in the modern world. I hypothesise that if everything loses dimensionality eventually, there will be a point where the increasing deprivation of sensory stimuli in the things we use will reach a threshold at which most people will feel terribly joyless and incomplete. And no one will be able to pinpoint why. The second and third-order effects from the lack of being grounded in the present felt experience would have something to do with it.
If you are a product designer or technologist—consider creating articles that somehow make up for this deficiency.
Rematerialisation Rituals
I don’t find a lot of joy in using some of our modern marvels. Broadly speaking, I dislike my phone, I don’t like using most software, and I can’t work remotely all the time. I have found myself compensating for the increased dematerialisation of the world with some rematerialisation rituals. I don’t always do all of these rituals regularly, but including just a little bit of these in my life has (in my head) helped with some background feelings of wellness. Here are some of them:
Mindfulness, which helps extract more out of low-dimensionality articles.
Working from a co-working space (as a remote worker).
Going out over staying in.
Hobbies that don’t involve digital devices.
In my case, it’s coffee brewing. Better yet, I also grind the beans by hand.
Investing in colour and texture—for clothes, rugs and articles that are often used.
Appendix 1: A narrative about a smart thing Apple did to wean people off their instinct against low dimensionality
Pure speculation, but allow me to weave this narrative. I’d say Apple’s iPhone was a big driver that moved a lot of people’s waking hours into low-dimensionality activities. The number of things one could do on this flat, buttonless, low-tactility panel was unprecedented. It might have been uncomfortable too, in a world that wasn’t used to this level of dematerialisation.
But Apple’s UI designers provided a bridge from the highly material to the highly ephemeral world to ease this transition. They made a lot of the early apps and interfaces skeuomorphic—it’s an old design trick where the designer carries some familiar elements of older technology onto a new medium. All the fake wood and leather, although a poor imitation of the real thing, did its job.
This surely would have helped make the transition less jarring. Eventually, these elements were stripped away once the visceral barrier had been overcome and people were enjoying the conveniences and power of the modern smartphone.
]]><![CDATA[We, the Citizens and Systems Thinking]]>2024-03-05T00:00:00+00:00http://blog.nilenso.com/blog/2024/03/05/we-the-citizens-and-systems-thinking
“No one can define or measure justice, democracy, security, freedom, truth, or love. No one can define or measure any value. But if no one speaks up for them, if systems aren’t designed to produce them, if we don’t speak about them and point toward their presence or absence, they will cease to exist.”
— Donella Meadows, Thinking In Systems: A Primer
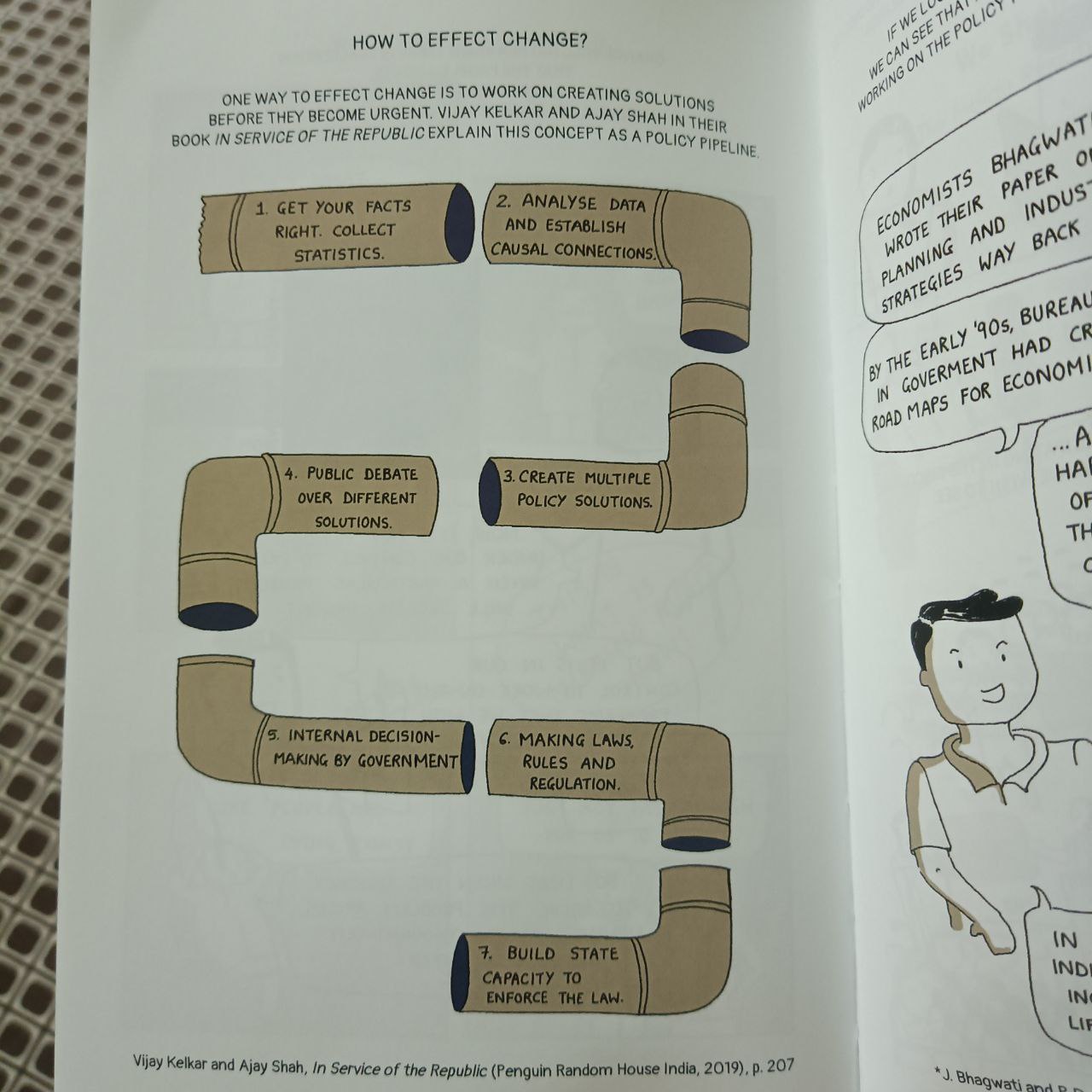
I recently bought this book which is a graphic explainer in the style of a zine. It explains how the interplay between the state, market and society affects all of us and how we, the Indian citizens can play a part in it.
In short, it talks about all the things that you love to have an opinion on but don’t put enough thought into. I don’t mean to roast you alone. I was like that too, and to some extent, I still am. Don’t believe me? Do you have a clear, first-principles answer to all these questions? Make sure you aren’t repeating someone else’s opinion on this and that you have deeply thought through the implications of your answers:
What really is a republic? How does it differ from a democracy? Why does it matter that India is a republic?
What should the State provide to its citizens? What should it leave to the markets?
What does the market provide to the citizens? What properties does the market afford on society?
What are all the tools, incentives and levers that the states, market and society have to create positive change? Which policy levers must we pull for what situations?
Understanding this crazy complex and dynamic system called India is hard stuff. But there are some fundamental things that everyone can understand—and knowing these things will help you be a well-informed agentic citizen, as opposed to a passive nihilistic whiny chump who complains about how everything sucks (without enough empathetic insight into why things suck).
In fact, these fundamentals can be explained quite succinctly in the form of a comic book that an 11-year-old can understand. I love that this exists.
(A cartoonist, a policy expert and an economist walk into a bar. They write a book that is neither boring nor cringe. It’s actually amazing. What.)
Here are some poorly lit excerpts I enjoyed. Maybe you’ll get a feel for why I liked this book.
I liked this bit because of how succinctly it presents the big flaw of democracy.
I love these two pages because I can personally relate to them. I happen to work with a non-profit that makes software for managing cardiovascular disease at scale1. The one thing I definitely noticed is that public sector units are thirsting for resources and quality staff like a dehydrated fellow stuck in the Atacama desert.
Nothing particularly special in this part. I just happen to be a sucker for the Sisyphus myth. There used to be a time when it used to weigh on me a lot more.
Why free markets are so powerful.
In contrast, here’s one of many ways that show why markets suck. I love how they summarised Akerlof’s “The Market for Lemons” in one page.
All the things that Governments (generally) do. The chapter goes on to explain everything in the neta’s jacket and neatly ties all of these tools together in a crisp 2-axis chart. Great stuff.
How to change things. A nice thing about this book is all the citations that point to other interesting work in policy-making and economics.
I do have one small criticism of this book. The authors couldn’t resist adding a joke or two about the culture wars that are present in India. There are a couple of boomer uncle caricatures who go around calling people anti-national and insisting that everyone stand up for the national anthem.
Why is this a problem?
There’s a blurb at the back of the book by Ajay Shah that says this:
“[…] Everyone who is interested in India should buy this for their WhatsApp Uncle”
I strongly disagree with the blurb. Ironically, the inclusion of this blurb at the back perfectly demonstrates why this book will not be persuasive to the WhatsApp Uncle. It simply alienates them and makes them the butt of jokes, instead of trying to get them to understand the nuances of policy. Even if they are a lost cause, they are part of the system. One would hope that all the WhatsApp uncles who run our educational institutions don’t notice this stuff and exclude this book from school libraries.
Anyhow, by the end of the book, I felt like I had read a graphic novel instantiation of one of my favourite books, Donella Meadows’ Thinking In Systems—our society is nothing but the beats of a large, dynamic system of goals, levers, feedback loops and information flows. And the book plainly lays this all out in front of the reader. I am really impressed by the amount of nuance they could capture with the format. Props to the authors for that.
This piece was originally published in Atharva’s personal blog.
footnotes
A really interesting systems thinking problem by the way. Much like the stuff talked about in this book, solving cardiovascular health at scale is setting up the right feedback loops and pulling the right levers in a dynamic system! ↩
]]><![CDATA[Leaky Bucket Rate Limiting]]>2024-01-13T00:00:00+00:00http://blog.nilenso.com/blog/2024/01/13/leaky-bucketHmm…leaky bucket? The first time I heard these words, it made me chuckle. I thought what kind of name is this for a rate limiting strategy.
But upon exploring it, I found it to be a rather simple and elegant strategy used in a lot of production environments.
But what are we rate limiting? The answer, well, depends on your business requirement. A very common use case is to rate limit requests from a user of your service in a given period of time.
How do you differentiate between different users? An easy way out for us is that we can rate limit based on the IP Address of the request and that’s what we are going to do.
Formal definition:
Leaky Bucket is a method used in network traffic and rate limiting to control the rate of incoming requests and manage potential traffic congestion. It works on a simple analogy of how water flows out of a bucket with a small hole at the bottom.
Here’s how it works:
Bucket as a Buffer: Imagine a bucket that represents a buffer for incoming requests. The size of this bucket determines the buffer capacity, which means how many requests it can hold at any given time.
Constant Requests Outflow: Requests leave the bucket (or buffer) at a constant rate, regardless of the rate at which they arrive. This constant outflow rate ensures that data is processed at a steady, manageable pace per user.
Incoming Requests: Requests arrive at the bucket at varying rates. If the incoming rate is less than or equal to the outflow rate, packets are processed smoothly.
Overflow Management: When the incoming rate exceeds the outflow rate, excess packets start filling the bucket. If the bucket fills up, new incoming packets are discarded and return a 429 - TOO MANY REQUESTS until there is space in the bucket again for the IP address.
Advantages
The Leaky Bucket algorithm is effective in smoothing out bursty traffic - turning a variable-rate input into a constant-rate output. It’s also useful in ensuring that the data processing doesn’t get overwhelmed during high traffic periods.
Applications
It’s widely used in packet-switched networks for congestion control, in APIs for rate limiting requests, and in various other contexts where it’s essential to regulate the flow of data.
I would highly recommend reading this redis article. It mentions some other rate limited strategies like fixed window, sliding window and token bucket rate limiting.
typeRateLimiterstruct{RedisDB*redis.ClientDurationtime.DurationBucketCapacityint64ErrorHandlerfunc(c*gin.Context,errerror)GetBucketNamefunc(c*gin.Context)string}func(rRateLimiter)handleIncrement(c*gin.Context,cacheKeystring)error{value,err:=r.RedisDB.Incr(c,cacheKey).Result()ifvalue==1{// Key didn't exist before, so// we just created it, and we need to set an expiryr.RedisDB.Expire(c,cacheKey,r.Duration)}returnerr}func(rRateLimiter)Limit(c*gin.Context){bucketName:=r.GetBucketName(c)currentBucketSize,err:=r.RedisDB.Get(c,bucketName).Result()iferr!=nil&&errors.Is(err,redis.Nil){err:=r.handleIncrement(c,bucketName)iferr!=nil{r.ErrorHandler(c,err)}c.Next()return}elseiferr!=nil{r.ErrorHandler(c,err)return}intValue,err:=strconv.ParseInt(currentBucketSize,10,64)ifintValue<r.BucketCapacity{r.handleIncrement(c,bucketName)c.Next()}else{fmt.Println("got too many requests")r.ErrorHandler(c,errors.New("too many requests"))return}}
]]><![CDATA[Spreadsheets and Small Software]]>2023-11-10T00:00:00+00:00http://blog.nilenso.com/blog/2023/11/10/spreadsheets-and-small-softwareor why we need more spreadsheets.
My father decided to get a whole bunch of new furniture made (like we all do at some point in our lives). New beds, doors, chairs, closets. A carpenter was hired. Many kinds of woods were looked at and some were picked. I was tasked with tracking finances for the whole exercise.
I dropped into a Google Sheet and got started. By the end I had half a dozen worksheets, a few pivot tables and a variety of formulas. The work finished over a couple of weeks. We paid out the carpenter from the calculations in the sheet.
As a software engineer, I like to write and appreciate good software (no, I pine for it) – easy to work with, easy to understand, amenable to change, and reliable. The sheet was none of these things.
I was compelled to take a close look at why it was so. It’s been a few months since. This is a quick summary of things I’ve found, some of my thoughts and what I’ve been up to with them.
My Spreadsheet problem
If you’ve spent enough time on a sheet you’ve seen these: copy-paste errors, finicky date formats, a mixup with a relative/absolute reference, some rows at the bottom missing from an average1, awkward VLOOKUPs, INDEX-MATCHes, workarounds for circular references2 and mega-formulas3. Put a few of these in a sheet and it gets messy very quickly.
I ran into some of the same problems
I made a master list of furniture items and some summaries out of it (total cost of labor, cost by furniture type etc). Each time I added new items to the list, I had to update all the dependent formulas4.
The cost of each item depended on the kind of wood used. I listed the wood prices on one side but they weren’t easy to look up across the sheet5.
The carpenter charged per furniture so his pay depended on the master list. He wanted to verify my math, and justifiably so. Who was to say I hadn’t missed a few numbers here and there? The verification process meant walking backwards from the final total, one hop at a time. The trail of numbers, so to say, was hard to trace.
I see similar problems when programming, except there’s usually a way to solve them there.
Small Software
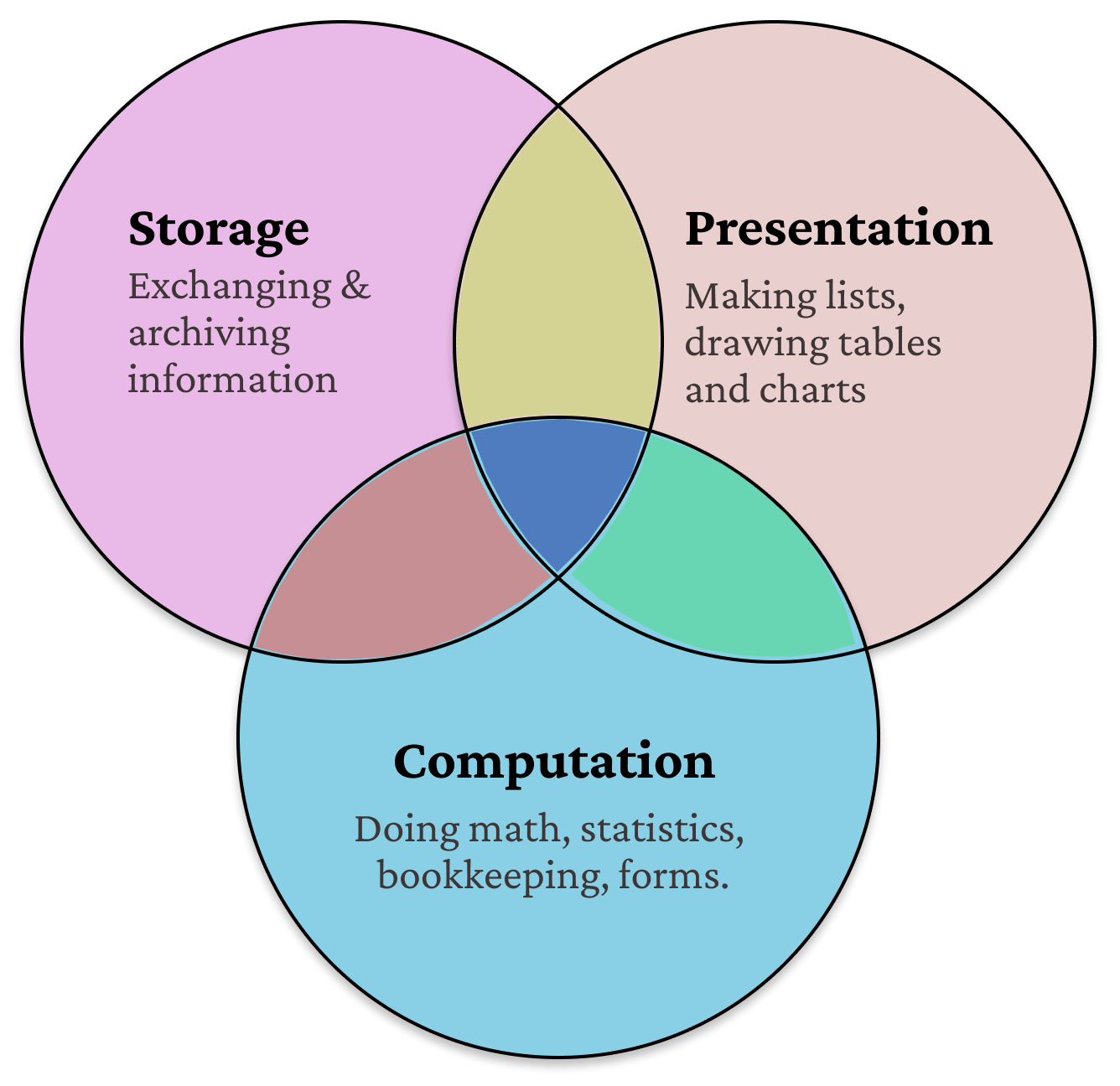
Spreadsheet usage falls in any intersection of Storage, Presentation and Computation needs.
People don’t always do all three. Spreadsheets are predominantly used for storage and presentation only – to make lists and lay out tables (todo lists, project management trackers, etc). Most of them don’t contain any formulas6. However for the (small group of) users whose work falls in the computation circle they’re uniquely powerful. I wouldn’t plan this work anywhere else. Nothing else fits. Nardi & Miller7 ascribe this to
Computational techniques that match users’ tasks and shield them from the low-level details of traditional programming, and
A table-oriented interface that serves as a model for users’ applications.
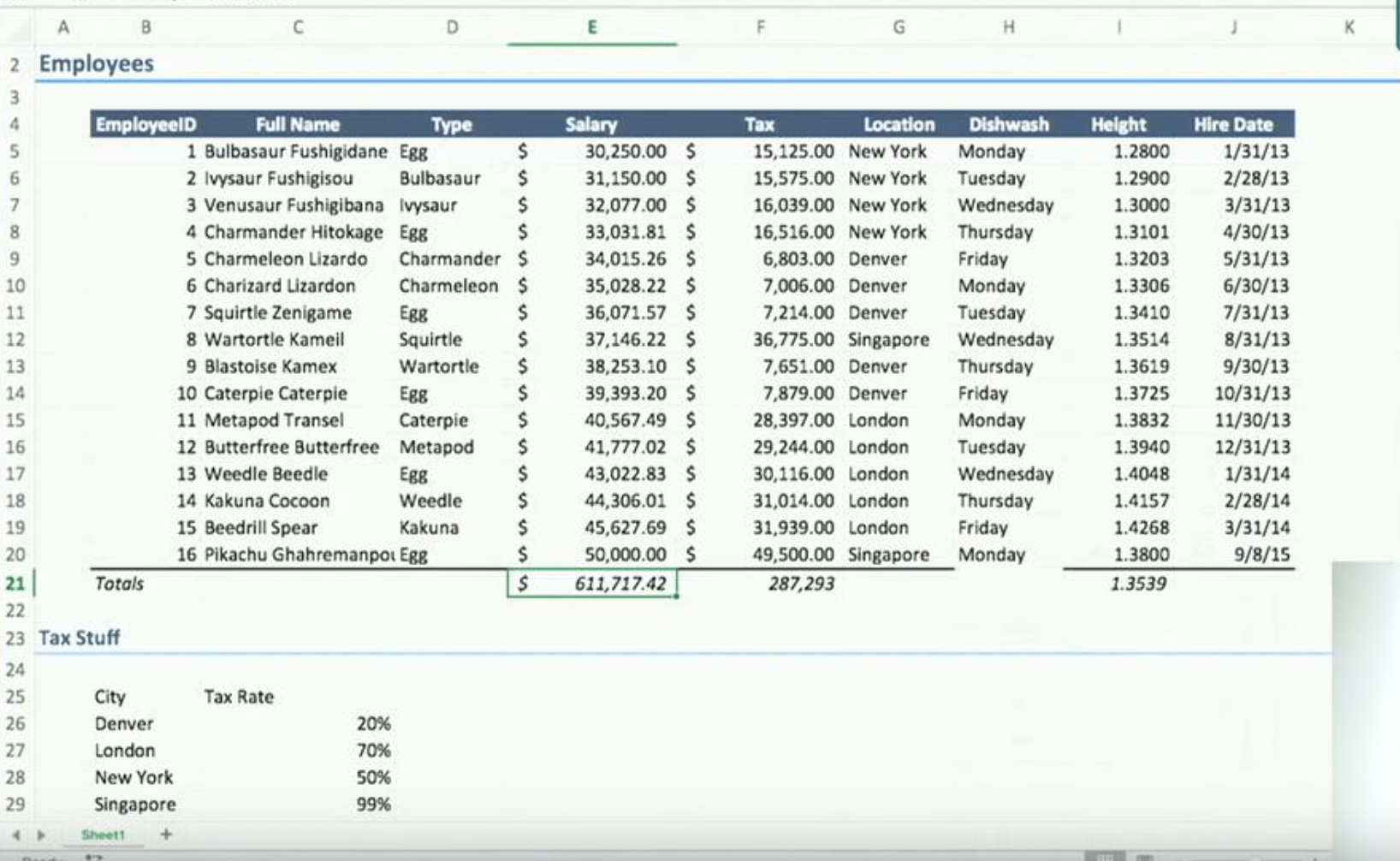
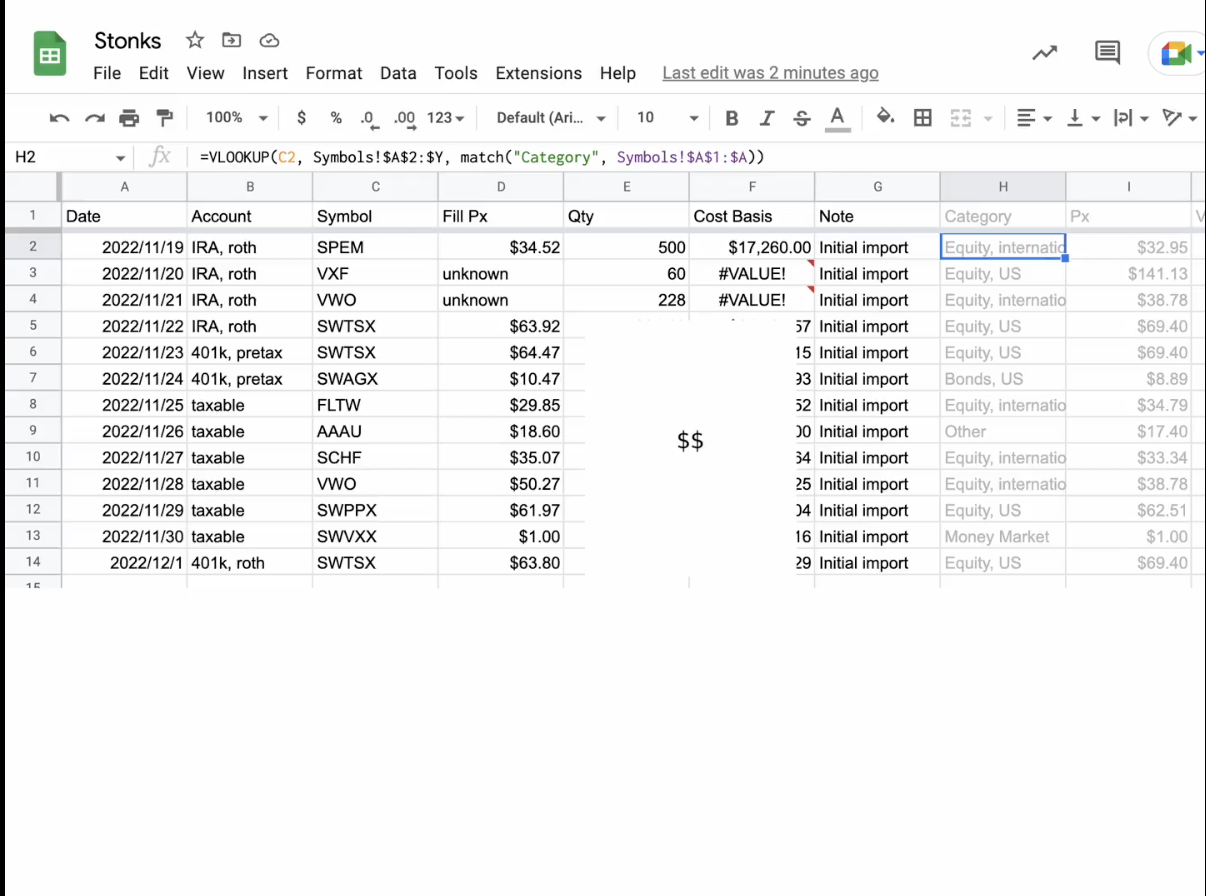
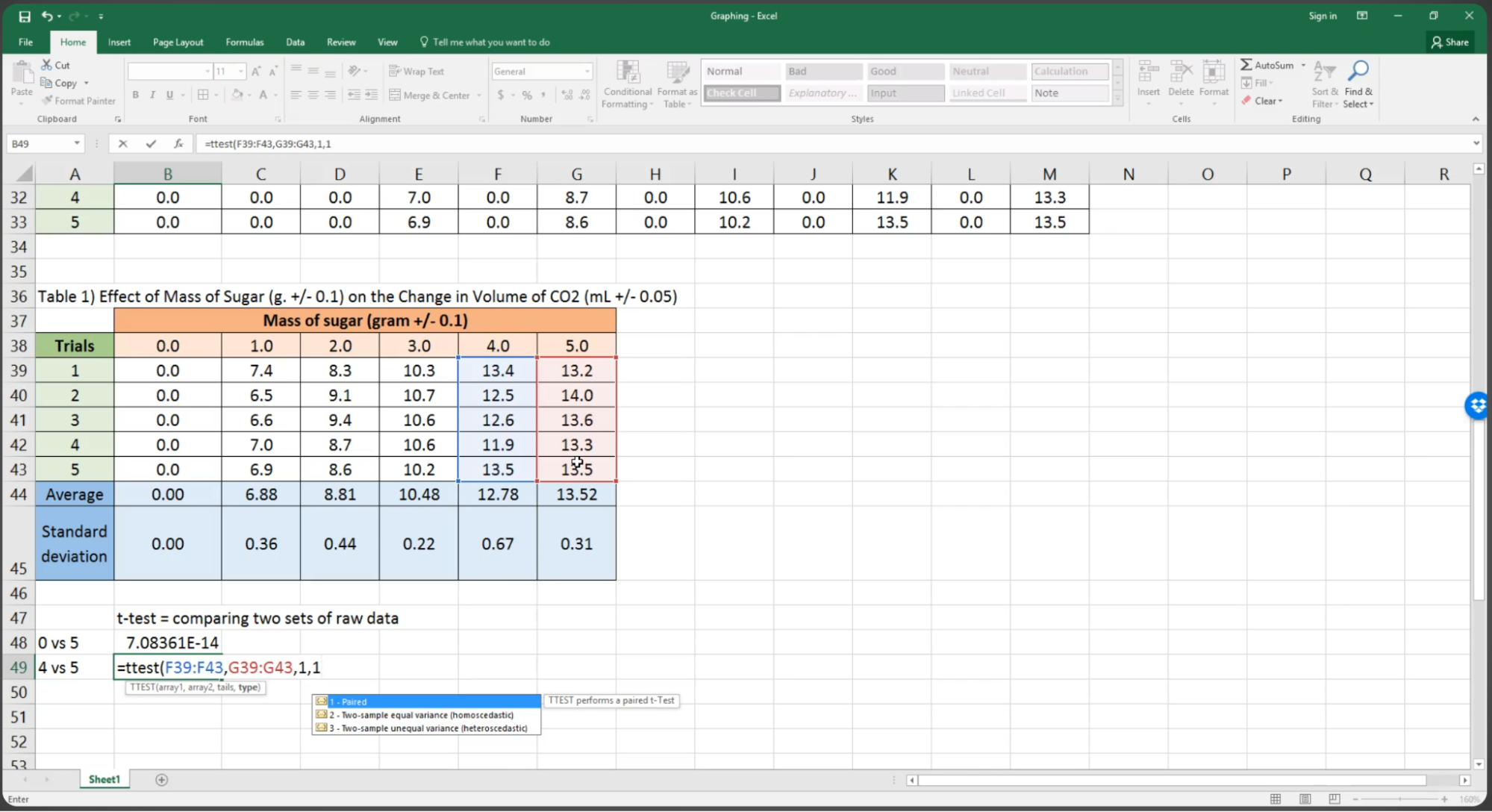
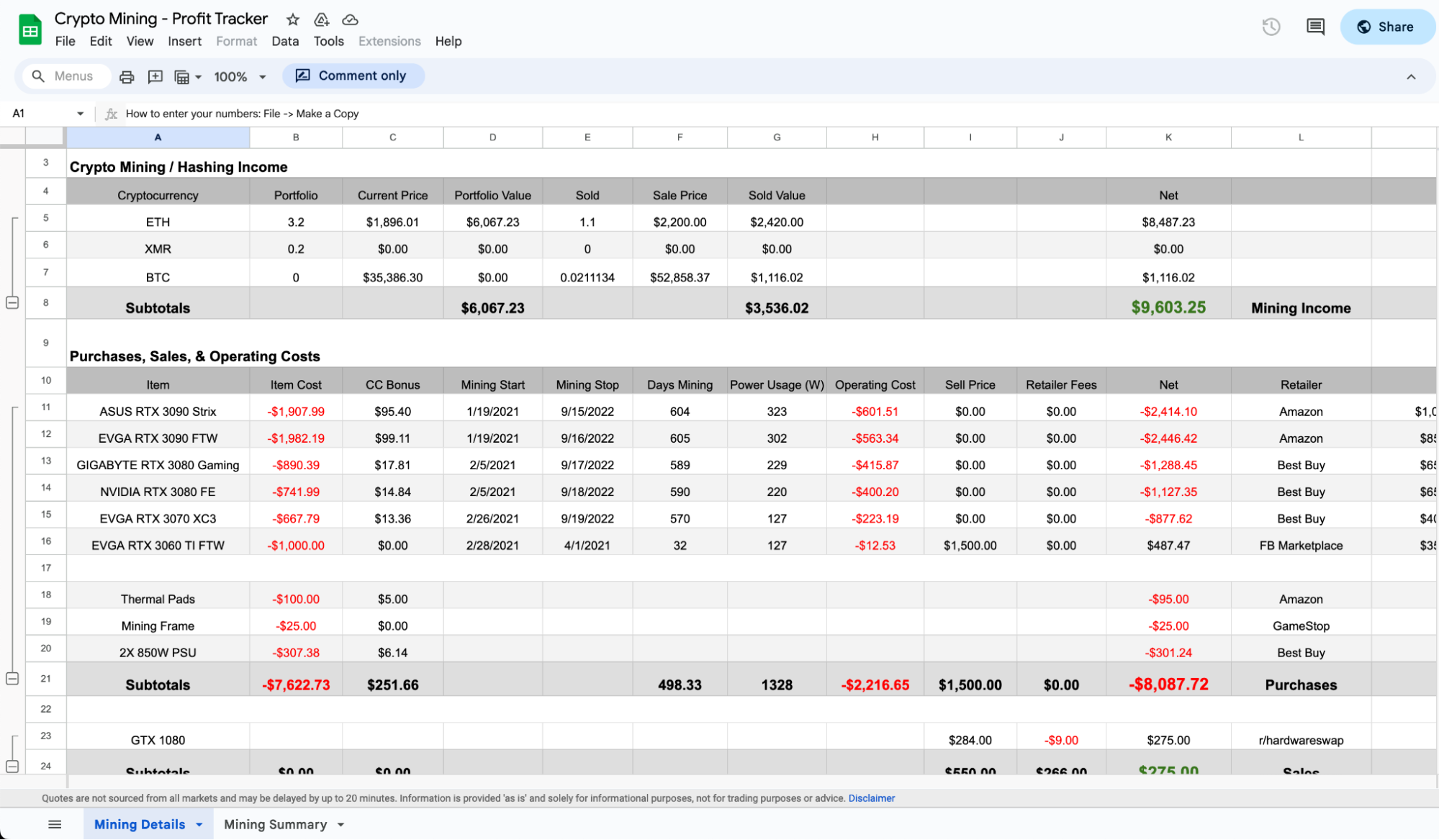
Here are some sheets similar to mine. A small company’s book of employees & salaries 8, a personal stock portfolio 9, a scientist organising some statistics 10, a crypto mining profit tracker 11.
These sheets are like regular programs in many ways. Felienne Hermans, a veteran spreadsheet researcher, puts it very simply: Spreadsheets are code12. She also goes on to show that they suffer from the same problems as real software.
❖
Simplistically, information systems are a place to put some information, do transformations on it (optionally) and look it up later13. A cash register, a cab booking app, a payment gateway, a search engine are all information systems in that sense. These sheets particularly are small information systems. I want to call them small software. The ask is dependable, good quality programs except their size – in surface area and complexity – is small.
Other names have been used synonymously (personal software, organizational software, end-user programs) but to me small captures the vibe well14. I also use small to distinguish from big software
Small implies it’s quick to make and get up and running.
It’s maintained by a small number of people, usually just one person.
While big software can employ a wide variety of powerful tools to build, small software cannot. The tools for building small things need to be simple, few and effective.
Spreadsheets in 2023
We wanted tools to make sheds, we got tools to make skyscrapers.
–– a tweet I cannot find anymore
If we posit that spreadsheets are small software, how do they fare on the qualities we’re looking for? Consider the following
Spreadsheet software is fully backward compatible to prevent breakage in old sheets, to the extent that newer ones preserve bugs from older ones15. Change is accretive and almost no features have been discarded in the last couple of decades16. Every spreadsheet needs to be compatible with MS Excel and carries its baggage.
There’s little support for structured programming concepts to maintain and debug a sheet. While there’s been some new additions (tables, named functions) they don’t fit as well.
As a symptom, errors in spreadsheets are commonplace and a big problem. There’s an interest group that tackles problems in this area and manyconsultingfirms that teach how to make good spreadsheets. Spreadsheet errors can cause damage very much like real software. They’re not as well understood which makes them more unfortunate.
Over the years, developers have arrived at some must-haves to build good software. We like to use good languages, write tests, peer review our code etc. Very little of this has made its way to spreadsheets so it’s not surprising they’re
Easy to spike in but hard to maintain and audit.
Riddled with errors, universally.
Hard to build robust processes around.
Harder to use than they should be.
In closing
One, I think the spreadsheet medium is nascent, by the measure of how much has and hasn’t been tried out. There are many bad primitives and very few guardrails. We don’t get a new spreadsheet every year. We do this with programming languages all the time.
New spreadsheets or spin-offs that try to solve these problems usually depart from the recipe in some significant way. Experimental ones and dataflowprogramming have their own place but they are all somethingdifferent. And it’s not reasonable to expect mainstream spreadsheets to solve this.
Secondly, I think patching your favorite programming language on top does not work well. Each language has its abstractions and ways of working, which may be at odds with the spreadsheet paradigm. Translating between paradigms has a real cost that a user has to bear. Users also realize that there are too many languages to deal with already and more of them is a problem17.
Thirdly, I think more people should be implementing their own spreadsheets. These things are probably not showing up in popular ones anytime soon
A simple and expressive formula language that supports its contexts of use.
Useful data structures that provide organization but don’t get in the way18.
Functions as a tool for problem solving, not just a place to tuck away gnarly formulas.
Tools to deal with change – Tests and Version control.
Good interop with other languages.
So we’re writing a spreadsheet at nilenso to try out some of these ideas. It’s intended to be a playground to implement things explored in theory and run experiments. Maybe eventually, it’ll become a full-fledged piece of software that I wouldn’t mind using. The plan is to write about the proceedings as we go.
Lastly, any other way of writing sane and functional programs requires a big commitment to learn and get started. The choice is between the scrappy utilities in existing spreadsheets and installing Python on your computer. I think spreadsheets still hold the promise of a well-formed environment for making small software; where the medium, the language, and the tooling works as one.
Thanks to Atharva, Prathyush and friends for reviewing this post.
There’s something to be said about how the rise of the finance industry has shaped the evolution of spreadsheet software. I’ll not say much but leave this bit from a show I thoroughly enjoyed watching. ↩
]]><![CDATA[A Software Analogy]]>2023-10-07T00:00:00+00:00http://blog.nilenso.com/blog/2023/10/07/a-software-analogyWhat contributes to a stable, high quality software product? I shall categorise it this way:
The mapping of abstractions and patterns to the problem.
Choice of tools and technologies.
Software discourse tends to be disproportionately focused on the latter. I find myself contributing to this skew as well. Perhaps it’s because tools and technologies are more concrete and easy to talk about. It’s also easy to get people worked up about it.
Yet tools and technologies only exist in service of the first category, which fundamentally capture the highest-value bits of a developer’s job—concept mapping. Or making analogies. Pick whichever phrase that makes the most sense to you. I shall present a short motivating example for what I mean by concept-mapping.
Designing a Sudoku Solver
Suppose you were to write a Sudoku solver. Our first job would be to make an analogy—how do I turn this concept that humans brains understand (“solving sudoku”) into a representation that a different processing substrate (here, your computer) can “understand” and process?
There’s so many possibilities! Here’s three of them.
The grid is analogous to an ordered list of 81 “places”. Each square on the grid would be mapped to a “place” on the list. We get the rows, columns and blocks (ie, the subgrids) for a given square by functions that do some modulo arithmetic on our 81-sized list. We also provide a function that tells us the possible values for each unfilled square.
The grid is analogous to a table that maps the names of squares to the value it contains. The “name” of a square could encoded just like a spreadsheet—A1 for the first square, A2 for the square to its right and B1 for the square below it. Unfilled squares contain a sequence of all possible values that could be inserted in it, while satisfying the Sudoku constraint.
The grid is analogous to a regular undirected graph of 81 nodes. Each node is connected to another node that belongs to either the same row, column or block. The solution to the puzzle is analogous to finding a way to assign 9 different colours to all nodes such that no two adjacent nodes have the same colour.
Each analogy lends itself to different problem solving approaches. The choice of analogy will affect a bunch of things like:
How easy is it to display the puzzle into a human-readable graphic?
How easy is it to enumerate all possible combinations of game-states?
How easy is it to propagate constraints (ie, if square X has number 3, then I am sure that there is no other 3 in the row, column or block)?
How efficient is the representation for the chosen substrate of computation?
Climbing out of the pit of on-off switches
What I have left out is the enormous amount of analogies that our Sudoku solving analogy is building on top of. Our computing substrate, encodes binary on-off switches (which our hardware is great at representing) to base-2 numbers. These base-2 numbers are itself used to encode computational verbs such as “add”, “subtract” or “check if something is zero”. These primitives give rise to higher-level procedures like “sort a list” or “turn this language into the instruction set that this procedure is written in”. Our Sudoku solving analogy will likely be written in the language that is transitively analogous to a bunch of on-off switches, which mirror what humans understand as “solving a Sudoku puzzle”.
What’s interesting here is the fact that as we climb out of this pit of analogies, the lower level analogies matter less and less. Indeed, when we were enumerating our ideas to represent a Sudoku board, we weren’t thinking of on-off switches, base-2 numbers or even instruction encodings for said numbers. We could safely ignore them, and yet provide meaningful value and understanding of how to tackle this problem.
If you are willing to entertain yet another analogy, the meaninglessness of lower levels is rather eloquently described by Douglas Hofstadter:
Consider the day when, at age eight, I first heard the fourth étude of Chopin’s Opus 25 on my parents’ record player, and instantly fell in love with it. Now suppose that my mother had placed the needle in the groove a millisecond later. One thing for sure is that all the molecules in the room would have moved completely differently. If you had been one of those molecules, you would have had a wildly different life story. Thanks to that millisecond delay, you would have careened and bashed into completely different molecules in utterly different places, spun off in totally different directions, and on and on, ad infinitum. No matter which molecule you were in the room, your life story would have turned out unimaginably different. But would any of that have made an iota of difference to the life story of the kid listening to the music? No—not the teensiest, tiniest iota of difference. All that would have mattered was that Opus 25, number 4 got transmitted faithfully through the air, and that would most surely have happened. My life story would not have been changed in any way, shape, or form if my mother had put the needle down in the groove a millisecond earlier or later. Or a second earlier or later.
What I am trying to say is that with a good abstraction, it isn’t the substrate where the magic is at, it is instead in the interaction or “motions” around the analogy boundaries. In the same way, Chopin’s étude is fairly robust to changes in the instrument, record player or performer (assuming all the notes are hit correctly). These changes in the substrate would likely still stir Hofstadter’s heart.
If the contracts between the analogy we are making and the analogies we are building on top of remain the same, the substrate broadly does not matter. If we could represent graphs, lists and tables using a computing substrate powered by quantum superpositions, cosmic rays and alignment of chakras instead of base-2 numbers, our Sudoku solving analogies would still hold. Or at least that’s the promise that an effective Software developer provides—”my analogy can stand well despite the shifts in the analogies and substrates below it.”
Which is why my definition of what a software developer is rather flexible compared to most people. She need not be a desk-jobber who writes a code on a text editor—the substrate is not important—a good software developer uses effective techniques to come up with analogies to solve problems.
The part where technology does matter
All this is not to say that our choices of technology does not matter—it only matters to the extent where it helps us make effective analogies. For example, I consider Clojure to be a more enjoyable programming language than Go, because I believe the former’s expressiveness helps me make more robust analogies. Then again, I also understand that there’s a lot more to analogy-making than the programming language I select. A hyperfocus on technologies (especially prevalent in junior developers) distracts from what I consider to be the business of making analogies.
The Sudoku Graph analogy. A bit out of my league, to be honest. I don’t know enough graph theory and didn’t spend enough time to read this.
Another fun analogy is to build on top of an analogy that understands “relations”. We use one of our representations and put it into a language that returns a “knowledge mapping” of terms that would help satisfy a constraint. Left this one out of the main blog post, because I am currently pretty bad at explaining it. But here’s a Sudoku solver that works on miniKanren/core.logic/Prolog(?) analogy modellers, if you are familiar with those (I am not).
The Douglas Hofstadter quote is from the book I am a strange loop which I highly recommend reading. It inspired most of this essay.
]]><![CDATA[FOSSMeet 2023: The brazen indifference for Free Software, because people think Something Else is more important.]]>2023-03-20T00:00:00+00:00http://blog.nilenso.com/blog/2023/03/20/fossmeet-2023Views in this article are those of Atharva, and not nilenso. The coop isn’t yet a hivemind.
After an afternoon replete with good food, coconut juice and punishing tropical heat, we went to the venue at NIT Calicut. As we waited for the microphones to be set up for the keynote, I had a chat with the soon-retiring professor who helped conceive FOSSMeet. He helped revive this edition of the conference after a three-year gap, and also had a part in the Free Software revolution in Kerala, which saw schools and government departments adopt Free Software.
He told me how important it is for this conference to continue. Young people these days are great with technology, and there are plenty of platforms to talk about it. What we need more critically is a platform to uphold the ideals and values of Free or Swatantra Software. That is software that respects the four essential freedoms. I used to think like the Professor. But on that day, I didn’t have the heart to tell him what I really thought about the state of Free Software.
Free Software has already lost. It’s all about what helps corporations now.
I observed that many of the college-age attendees could not differentiate between Free Software and Open Source software. This was juxtaposed with an abundance of stickers and merchandise containing playful references to Richard M Stallman, the founder and larger-than-life figure that looms over the Free Software movement 1.
A lot of corrections and disambiguations were made over the next three days. With a few people prefixing their questions with an apology for still using Windows.
There were also some of the older speakers and Free Software supporters that made appeals to adopt and use Free and Open Source Software. Throw away the proprietary stuff run by large corporations who don’t have your best interests.
These ideals are great, I thought for a second. But this train of thought derailed soon.
Nearly all the great open-source alternatives being suggested here are fuelled and funded by the same giant corporations we are rallying against. That’s why we are getting to use it for free. GitHub is owned by Microsoft, and that’s where nearly all Open Source software lives.
I thought of the pride that some college professors and authorities would have if their students got placed in Microsoft or Google.
The talking points continued to be dispensed. Encourage freedom-respecting alternatives, even if they are slightly worse. The beauty of FOSS is that if something does not work for you, or if a feature is missing, we can always fix the software ourselves and share the changes back to help everyone else. My dissonance grew.
Yeah right. If the WiFi driver on someone’s laptop breaks, almost no one will spend their time learning kernel programming to figure out how to fix it. The same goes for most Free Software. People don’t have the expertise or time. The burden of ensuring that things work goes to thankless, burnt-out maintainers, or centralised entities (ie, big corporations). And what about the underpaid schoolteachers and officials in the rural districts running FOSS? Are we going to tell them to go fix everything for themselves?
The success stories of FOSS adoption in schools and governments were brought up.
Was FOSS adopted by the government merely to save costs? Do they even care about the four freedoms? Will they bother giving back to the community?
As the conference went on, my thoughts inner monologues got louder. I grew uncomfortable. Anyone who has read about mindfulness practices would know that denying reality causes stress and suffering.
We have our Free Software (and our Proprietary Software, and whatever software). Yet the world still ails from injustice, disease, poverty and suffering. If this conference is about something greater than cool technology, why aren’t we getting to the heart of the matter? What is the heart of the matter?
And on the morning of the second day, I felt we had suffered enough. I slanted over to fellow ensonians Prabhanshu2 and Akshatha and said, “Maybe there’s room for a talk full of bitter pills and harsh realities. It might offend, but it needs to be talked about.”
Quite wonderfully, my request for the world was willed into existence. The next speaker in line, Akshay S Dinesh, stepped up and supplied the bitter pills I was seeking, but he made them taste sweet with his fun, highly interactive talk, amusingly titled “Enough of JavaScript build tools. Solving real-world problems collaboratively through FOSS, etc”.
He laid out percentage figures with no descriptions in his slides and made people guess what these were. And systematically, the realisations started reverberating. The top 10% held around 70% of the nation’s wealth. If we owned a scooter, car or house, we were likely in that top 10%. He talked about catastrophic health expenditures and how a large chunk of Indians without our privileges are vulnerable to losing their wealth to medical emergencies. He talked about the prejudices that still exist in society and the mess we’re in.
Something changed for me in this Free Software conference, which until now was like many other such events, teeming with usual appeals to adopt Stallman-certified software. Now it finally felt like something more. We are finally talking about the big picture. Free Software might have tried to address this at some point. He laid bare what really ails us.
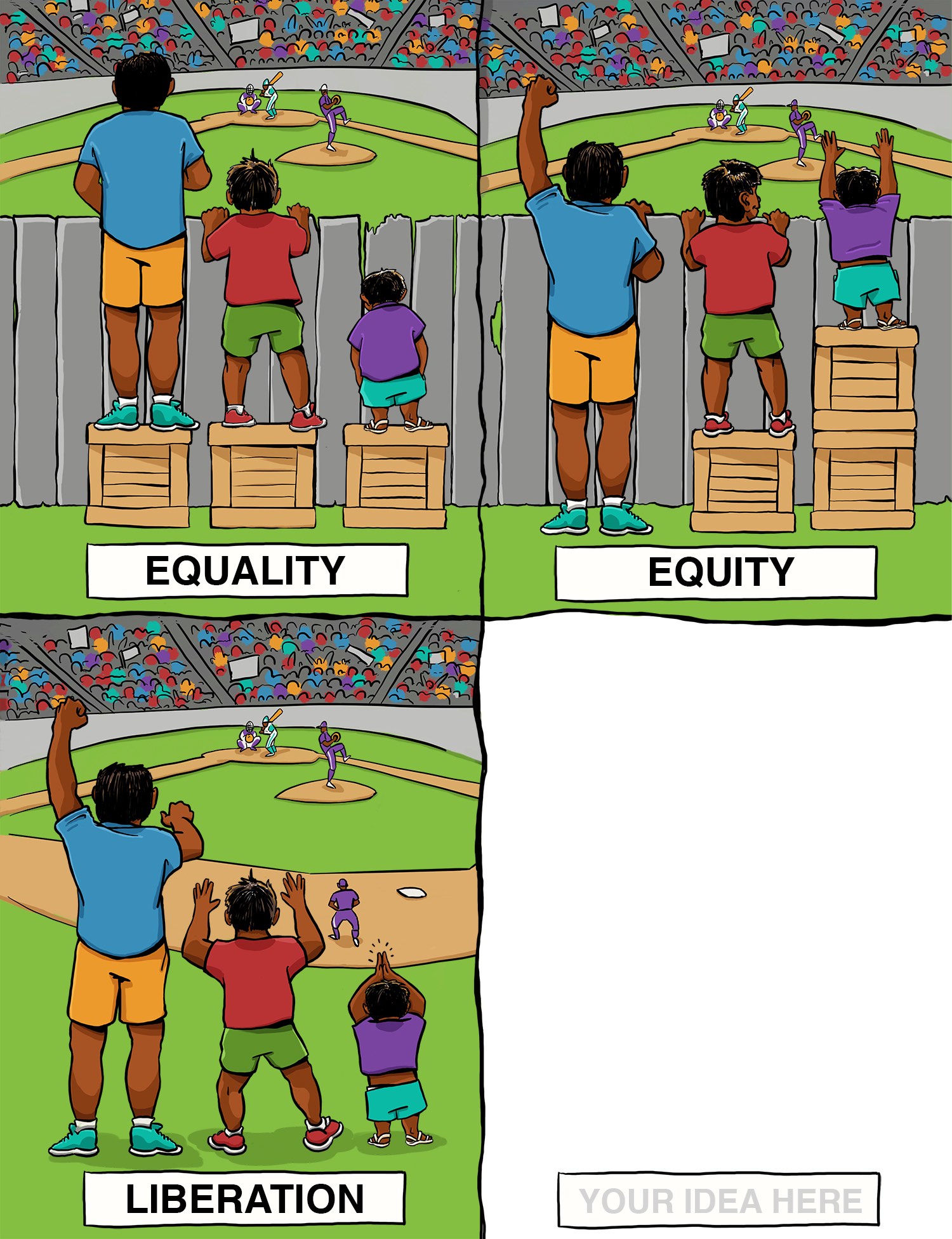
He left the audience with an exercise called “The 4th Box”3.
Each box displays the various attempts to fix injustices in our society. The first one is to apply the same solution equally, not accounting for the privileges people have. The other is something like affirmative action, where you solve each person’s needs differently, to get an equal outcome. The third box is to remove the obstacle entirely (why was it even there?). The fourth box is blank. It’s because there aren’t just three ways to address it. We need all of the good ideas we can get and more of them.
And right after he showed this, came the money line, which brought us back to Free and Open Source Software.
FOSS is an option.
It’s not the solution. It’s just an option, and not necessarily the best one. Use it with all the other tools in the box to help make the world more equitable.
Akshay did not talk about JavaScript.
. . • ☆ . ° .• °:. *₊ ° . ☆
I met some of the other speakers in the lunch break, mostly young whippersnappers like me who are all bundled up in a polythene bag labelled Gen-Z (usually by overly-confident journalists).
These were people like me, who were drawn to FOSS movements and had their fair share of contributions to various communities. And like me, they shared the same varietal of scepticism about FOSS. It was clear what the younger folks at the conference were focused on. We wanted to solve problems. We didn’t want to be activists tied to a cause. Use the tools we have to make the world better and get on with it.
There was the technical chatter too, of course. I was talking about TypeScript to the CTO of a company that runs a popular Open Source project. Types are a layer of restrictions added over JavaScript that guarantees the elimination of certain classes of errors. The debate we had was that while it’s useful to have these restrictions to protect fallible humans from themselves, we also eliminate a really large set of programs that are perfectly valid only because the type system doesn’t accept them. It’s a tradeoff.
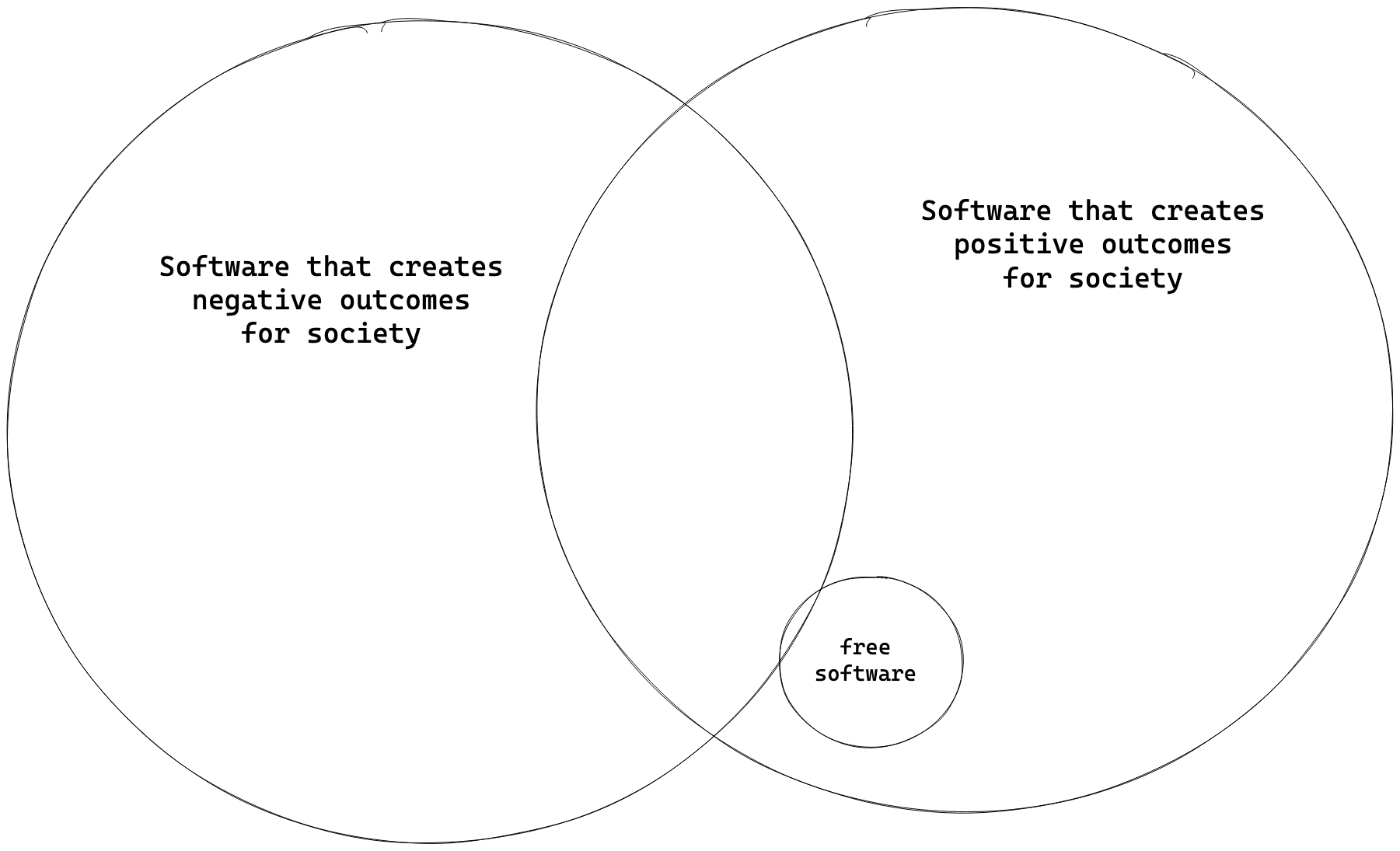
I’d like to think about Free Software similarly. It’s a set of restrictions over the licensing and distribution of Software that if followed, will guarantee some good outcomes for society. It’s much harder to exploit your users when your program can be used, modified and inspected in pretty much any way. For example, if my local hospital’s patient management software met the Free Software definition, I would be able to verify if it did something nasty, like transmitting my prescription data to third parties. Moreover, a rural clinic would theoretically be able to take the same software and adapt it to make it work better in internet-scarce regions. Quite neat. But slapping a GPL licence on the patient management software would still not stop a malicious hospital from producing a data dump of all its data and selling it. They could still exploit their users if they really wanted to.
Stallman’s definitions of freedom will also rule out large classes of perfectly-good-for-society software with the villainous label of “unethical”. The Free Software Foundation is quite aggressive about things not meeting their standards. They see a binary, where there is a spectrum.
Stallman would lament the fact that my colleague Prabhanshu is working with MIT-licensed software at Simple. This license won’t meet the Free Software standards of “ethical” because someone could theoretically make modifications and deploy a proprietary variant that cannot be audited or trusted. While this is true, it does not change the fact that Simple is a software that has created highly positive outcomes for society. More so than a lot of software licensed in a way that would satisfy the Free Software maximalists.
And that’s why I am largely indifferent to Free Software as an ideology. Some say it’s dying, and others argue it’s already dead. I haven’t checked the pulse. I am not interested in another subculture that lives and dies by the holy words of its greatest founder.
The world is magical, but there are no magic spells. We don’t only need Free Software. We need something with a bigger frame, something more complete, and more of it.
Footnotes
Enough has been written about this guy already. I’ll save some words in this essay. ↩
Prabhanshu gave a talk on simple.org, a software he worked on which saves lives in rural areas. ↩
Image Credit: A collaboration between Center for Story-based Strategy & Interaction Institute for Social Change. ↩
When someone told me about beanstalkd, the seed of an idea was planted
in my mind. I had some free time on my hands and decided that I wanted to implement it in
Clojure to learn a thing or two. The simplicity of the beanstalkd protocol
appealed to me, and it seemed like something I could implement. In addition to this,
a preview build of Project Loom was made available, and I wanted an
opportunity to try out virtual threads. Over two months, this germ of an idea sprouted into the
2400 line sapling it is today. I referred only to the
beanstalkd protocol, and didn’t
read any of the beanstalkd code. Here’s how it works:
Clients, Jobs and Commands
A job is a description of some task to be done. In beanstalkd, jobs are binary
blobs. For simplicity, jobs are strings in small-stalk.
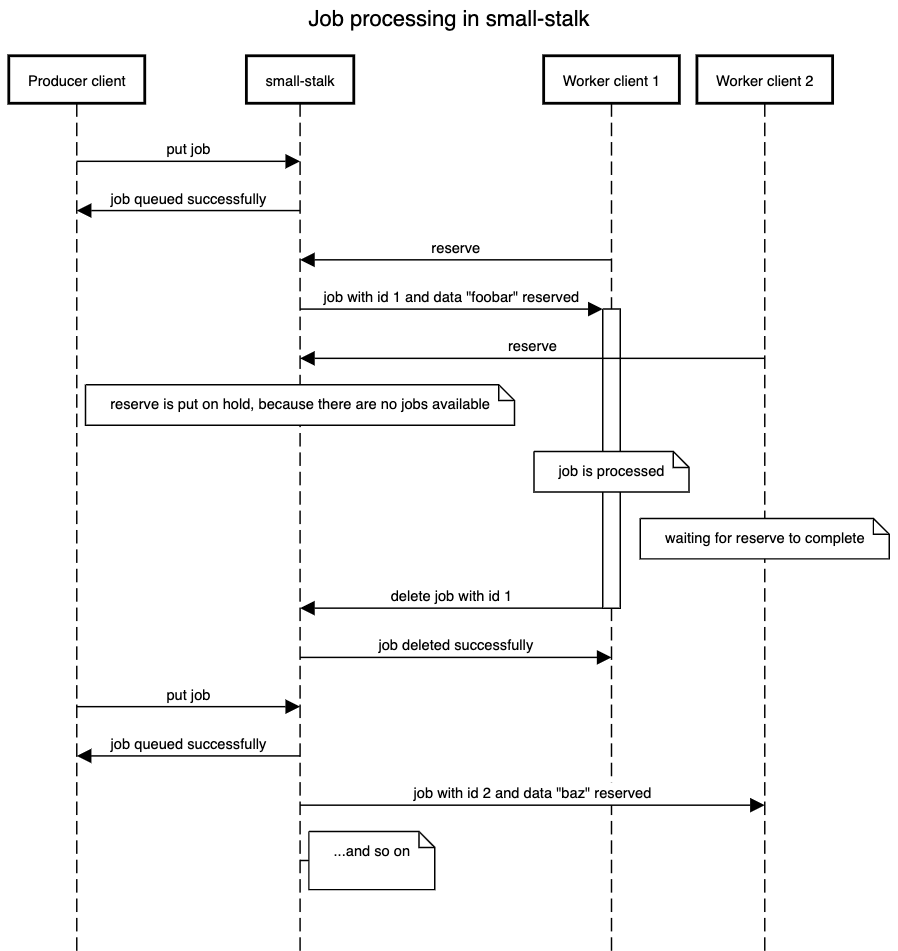
Here's how jobs are processed in a system using small-stalk:
There can be two types of clients of small-stalk: producers and workers. Producers
submit jobs to be executed, and workers consume and execute these jobs. Note that
small-stalk itself makes no distinction between clients, and any client can run any
command.
put <priority> <time to run in seconds>: Puts a job into
small-stalk’s queue. The job string should be sent on the next line.
peek-ready: Returns the next available job without removing it from the queue.
reserve: Pops the next ready job and assigns it to the client to be run. If
no job is available, it blocks until a job becomes available.
reserve-with-timeout <timeout in seconds>: Like reserve, but blocking
times out after the given number of seconds.
delete: Removes a job from small-stalk. Typically used on a reserved job when
a worker has finished running it. Reserved jobs can only be deleted by the
client that reserved them.
release: Un-reserves a job and puts it back into small-stalk’s queue.
Typically used when a worker fails to complete a job and wants it to be retried.
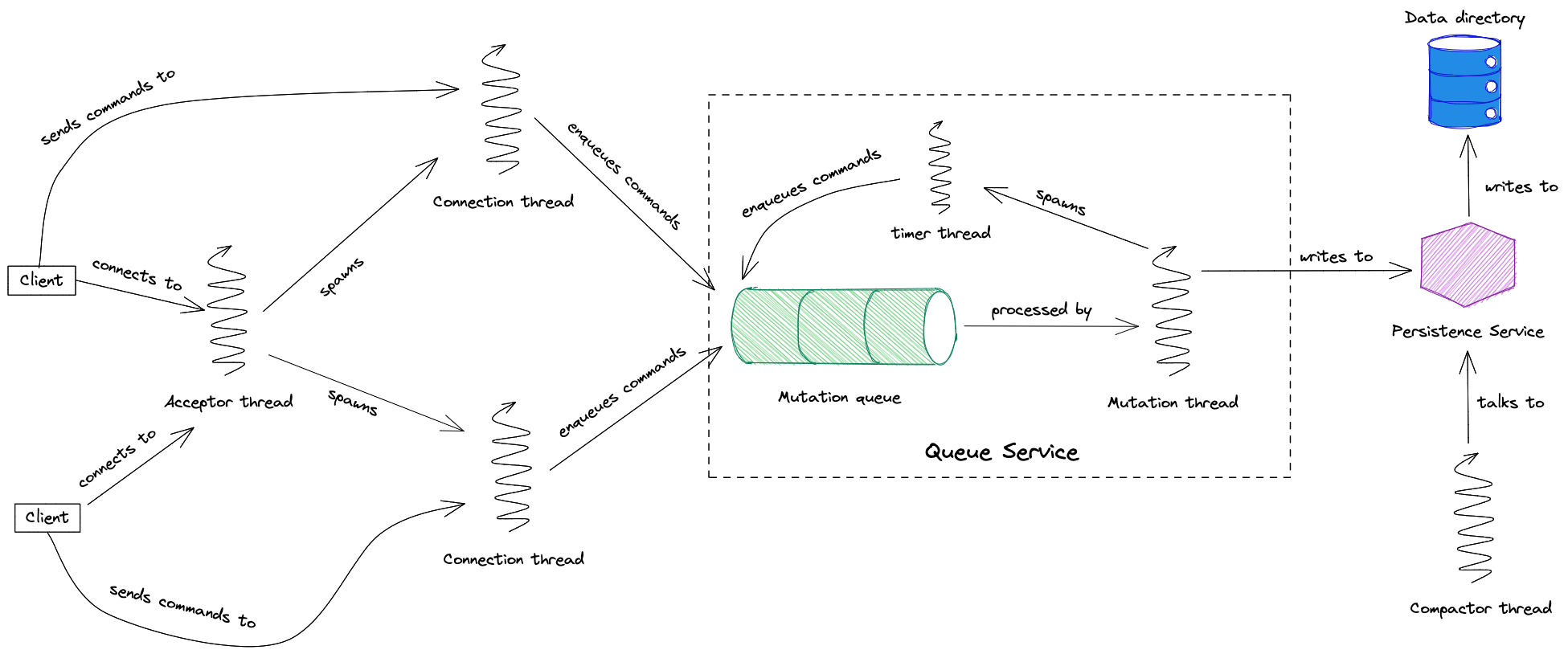
Architecture
small-stalk’s acceptor thread listens on a port for incoming connections. When a connection is made, a connection
thread is spawned to process commands sent by that client. The cheapness of virtual threads makes it possible to
spawn a thread per connection, even if there are thousands of clients. Each connection thread reads commands, parses
them and hands them off to the Queue Service for execution. The Queue Service uses the Persistence Service to
persist the queue state to disk. The compactor thread regularly tells the Persistence Service to clean up data files
on disk to save space.
Virtual Threads
Virtual threads are the JVM’s answer to goroutines and Erlang processes.
They can be created much more cheaply than conventional OS threads, making it possible to create a thread per
connection even if there are thousands and thousands of clients. Virtual threads are not available in a stable JDK
yet, and I used a preview build of the JDK in order to try them out in small-stalk.
Connection Registry and Connection Threads
When a client connects to small-stalk, it is assigned an ID and its socket is stored in a registry. Identifying
clients is necessary for some commands like reserve and delete, since if a job is reserved, only the client that
reserved a job is allowed to delete it.
A virtual thread is spawned for every incoming connection. These connection threads take care of reading and writing
data from and to the connection socket. The connection threads parse commands from text and hand them over to the
queue service for execution. small-stalk does not support pipelining, which means that clients are expected to read
the response of the previous command before sending a new command. Connection threads block until the Queue Service
is done executing a command, because the Queue Service exposes a synchronous API.
Queue Service
The Queue Service is a combination of:
Data structures that maintain the state of jobs,
A mutation queue into which incoming mutations are queued, and
A mutation thread which reads mutations off of the queue and executes them.
I knew that I wanted to use some kind of append-only log for persistence, since I thought this would be easier to
implement than complex data structures on disk. This led me to the idea of serializing all data changes in a queue.
A mutation is a data representation of a change that must be made to the queue data structure. All mutating commands
(i.e. commands that are not simple reads like peek) map to a mutation. There are also other mutations (such as
::time-to-run-expired) that are triggered by timers rather than by a connection
thread.
All mutating commands made by connection threads are converted into mutations and enqueued into the mutation queue,
to be later executed by a single mutation thread. This means that all state changes are serialised. While this may
seem like an unnecessary performance bottleneck, it affords several benefits:
The state manipulation code is greatly simplified, because synchronisation isn’t a concern.
Having a log of mutations means that we can serialise mutations, send them elsewhere and then replay them to
reproduce the server’s exact state. This is how AOF persistence is implemented, and we could also ship them over
the network to a replica server to maintain as a hot standby.
Timers and Blocking
Since the Queue Service needs to expose a synchronous API, mutations are enqueued along with promises
to which the mutation thread can deliver return values. reserve, in particular,
needs to block until a ready job is available. To facilitate this, if a reserve
mutation is processed and no job is available, the reserve mutation along with its
return promise is enqueued into a separate queue for waiting reserves. When a new job is added, the mutation thread
checks the waiting reserves queue and fulfils a waiting reserve, if any.
The reserve-with-timeout command offers a timeout on the reserve blocking. To
implement this, a separate timer thread to cancel the reserve is launched. This thread does not mutate the state
directly, but instead enqueues a special mutation indicating that the client’s timeout has expired. All state
modification, including cleaning up and cancelling the reserve, is done by the mutation thread.
The time-to-reserve timeout works in a similar way. When enqueueing a job, the
client can specify how long a worker should be allowed to keep a job reserved. After this timeout expires,
small-stalk will automatically release the job. Again, a separate timer thread is launched when a client reserves a
job. This thread enqueues a time-to-reserve-expired mutation, which is then handled
by the mutation thread.
Persistence Service
The Persistence Service is a collection of functions and data used to persist mutations processed by the Queue
Service. Mutations are persisted before they are processed. The file format is a simple newline-separated list of
EDN maps. Each map is a mutation. Mutations are appended to the file, one after another. This file is called an AOF
(append-only file).
To prevent disk usage from getting out of hand, every so often, mutations in the AOF file are processed and replaced
with a snapshot of the Queue Service’s state. This is done by the compactor thread. To facilitate this
process (called checkpointing), mutations are actually split over multiple AOF files. One file can hold at
most a configurable number of mutations. Once this limit is reached, a new file is created and new mutations are
appended there. The compactor thread reads mutations from all but the newest file (to which mutations are currently
being written), replays the mutations to build a state snapshot, then persists that snapshot to disk. Once this is
done, the older AOF files are deleted.
To facilitate testing, the Persistence Service is stubbed out with a service that simply writes mutations to a
string instead of the disk, and the compactor thread is not started.
Persistent Priority Queue
In order to work with Clojure’s reference types, the queue data structure is immutable, implemented using a
combination of Clojure’s immutable data structures.
Clojure offers an obscure but useful PersistentQueue data structure. However, this doesn’t support priorities.
small-stalk’s Persistent Priority Queue is implemented as a map of priority numbers to PersistentQueues. Popping an
element from the queue involves finding the smallest key, and popping an item from the corresponding
PersistentQueue. Unless the number of different priorities grows to be very large (which is unlikely for most use
cases), this is a fairly simple and efficient implementation. The map could be replaced by a sorted-map to make this
even more efficient.
Testing
Separating the networking layer from the queueing system allowed me to easily unit test the Queue Service without
having to send CRLF-terminated strings over a socket. Using a dependency injection framework like integrant also
allowed me to construct and stub out stateful components as necessary in tests. Although I didn’t take the time to
write end-to-end integration tests, those would be very helpful as well.
Possible Fixes and Improvements
small-stalk is not without issues, which I haven’t had time to address yet.
What happens if a client reserves a job and then disconnects? If the job has no time-to-reserve, it will live in
memory forever. When a client disconnects, its reserved jobs should be automatically released.
What happens if the server crashes during compaction, after the new snapshot has been written but before the old
AOF files have been deleted? small-stalk would replay the old AOF files on top of the new snapshot. Each
mutation should have a monotonically increasing ID and the snapshot should have the last ID of the mutations
used to build it, so that older mutations can be skipped if necessary.
What happens if the server crashes during compaction while the snapshot file is being overwritten? The snapshot
file would probably be corrupted and there would be no way to recover. small-stalk should write a new snapshot
file and delete the old one later, to allow for a recovery path in case of corruption.
A handful of recipes from the people at nilenso for your reading pleasure.
These have all been tried by real cooking noobs and are hopefully simple
enough for anyone to follow along. Having said that, if you do burn your
cookers don’t @ us on twitter or instagram.
Sandy’s French toast with stewed apples
For the toast, you will need
Eggs
Milk
Sugar
Bread
Butter, preferably unsalted
A bit of oil
Bonus
Chocolate sauce
Cinnamon powder
For the stewed apples
Apples
Butter
Honey
Sugar
Water
Break two eggs, add a bit of milk and sugar and mix it up. I use a fork
for this typically. If you have chocolate sauce you could add it to this
batter directly, cinnamon also. You'll dip the bread into the batter and
then fry it on the pan, so make sure the bread fits into whatever it is
you're using to make the batter in. I usually break the eggs into another
pan or a walled plate. In my experience, two eggs is usually enough for
six slices of bread, which serves two.
Then, put a pan on the gas. Add a tiny amount of oil, it's just to prevent
sticking and prevent the butter from burning. Put a bit of butter on the
pan. Then take a slice of bread, dip both sides into the batter, let the
excess batter run off and then fry the bread. Be sure to do both sides.
Repeat until you run out of batter. Try not to overcook the toast, I think
it's nicer when soft.
You could eat the French toast with jam or something if you want, or you
could make the apples like I'm about to tell you.
Slice up an apple into bite sized chunks. Lightly dust the bottom of a
vessel with sugar and melt it. Be very careful, if you heat the sugar too
long it'll burn, and if you let the sugar cool off it'll stick to the
vessel and become a real pain in the ass. No pressure. Add the apples in
at this point along with some butter, mix it up nicely. I've also added
honey in at this point as well, that's quite nice. Then add a bit of
water. The apples should be partly submerged. Let them simmer on the
stove. You want the water to evaporate.
You'll be left with the apples and some very sweet sauce as well. Usually
I prepare the apples in the vessel, let them simmer and then start with
the toast. They'll get done together.
Put the apples and sauce over the French toast and enjoy.
“Sandy's french toasts are p yum. Especially when it's already made
and left on the kitchen counter by him for you to eat.”
- Prabhanshu
“Fantastic. The apples were very surprising.”
- Akshatha
Prabhanshu's dry khichdi
Tadka in a pressure cooker:
Heat ½ tablespoon ghee for a minute
Mustard, cumin
4 kaju, 5 kishmish
A pinch of hing
Finely chopped lehsun if you’re feeling adventurous
When Tadka is done:
x cup rice, x/4 cup split (green) moong dal, 3x water.
Red chilli, turmeric, dhaniya powder, salt.
3 whistles on high heat, 1 on low heat, let it sit for a while.
The whole exercise takes around 12 minutes.
(misrepresentation)
“Simple, high ROI recipe that will make you feel like ten times the
cook you actually are. The controversy generated by the raisins cements this
recipe's place as a work of art.”
- Sandy
“Used the wrong dal, the wrong red chilli and had no idea what
consistency to expect but delicious. Nifty use of dry stores. 10/10
kajukishmish” - Akshatha
Priyanga’s tomato curry
You will need
1 medium size onion
3 tomatoes
2 green chillies
2 tsp chili powder
¼ tsp turmeric powder
¾ tsp salt
1 tsp mustard
3 tbsp coconut oil
Few curry leaves
Heat the oil, add mustard and curry leaves. After a few seconds add
onion and saute till transparent. Add chillies and tomatoes. Close the
lid and let it cook on high flame.
After 3 min smash and saute it until the tomatoes are fully cooked.
Now add the chilli powder, turmeric powder and salt. Mix it well and
add some water. Cook until it boils.
“I over-improvised a perfectly self-contained recipe and regretted
the results. Looking forward to trying again.”
- Akshatha
Akshatha’s miloats
This one has no real value add over reading the back of the packet of
oats you buy and
Milo is not available in stores anymore, but here it is
irregardlessly:
Get 1 cup milk on medium heat
Add ¼ cup oats to it
Boil till soft and cooked (~3m for my kellogs)
Mix in 1½ heaped tbsp Milo and bring it off heat
Dice any over-ripening fruits lying around though citruses are a bad
idea probably. Add to oats
Have warm
“It was pretty decent I would say.”
- Akshatha
Atharva’s Optimal Scrambled Eggs
Good scrambled eggs are all about that texture. It should be smooth and
creamy like a custard, with chunky and gooey curds. You need:
Eggs
Salt
Butter
Either corn starch or patience
Recipe
Whisk eggs nicely and salt them.
Optional: add cold butter chunklets which create cool localized
pockets while the eggs cook, which adds more variation to the
texture.
If you have cornstarch, make a bit of slurry and whisk it into the
eggs. If you don’t have cornstarch, you need patience for the
same result (explained later).
Put some fat on your pan, butter prolly
Once your butter is foamy, but not brown, put in the eggs
Now keep stirring it. If you have cornstarch added, the eggs
won’t tighten up and become rubbery that easily, so you can
take it chill. But if you didn’t add cornstarch, do not let
those eggs sit on the pan for a second. KEEP STIRRING IT LIKE A
LUNATIC.
Now for the people who opted for patience:
Keep stirring it and do not keep it on high heat. As soon as you
feel like the eggs are slowly starting to solidify, turn off the
heat and take off the pan and keep stirring.
Rinse and repeat this, depending on how many eggs you are cooking,
this may take even 10 mins.
(misrepresentation)
“Couldn’t discern the texture, overcooked it and made
regular scrambled eggs, but it turned out damn delicious. Best thing
about trying to get this right is that the baseline is pretty
delicious.”
- Akshatha
“Am I going to hype up these scrambled eggs? I guess I am. Let me
tell you, if you nail this thing, you are going to have the best
scrambled eggs in your whole life. Possibly the best egg anything in
your whole life. It’s really that good.”
- Atharva
You’ll know it’s done once you get this thick, creamy, chunky
texture. And stop the heat before you think it’s ready. The egg will
continue to cook in its heat. I only learned too late about the cornstarch
shortcut. The main concept is that you gotta let your eggs cook really
slow. Basically, torture the eggs and make them almost solidify but not
quite every time.
Eat it with some mildly toasted rustic bread. Wheat bread also works. If
you are feeling fancy a thick hunk of sourdough would be perfect.
]]><![CDATA[Offline-first apps are appropriate for many clinical environments]]>2020-01-02T00:00:00+00:00http://blog.nilenso.com/blog/2020/01/02/offline-first-apps-are-appropriate-for-many-cliniA nurse using the offline-first Simple app in rural Punjab
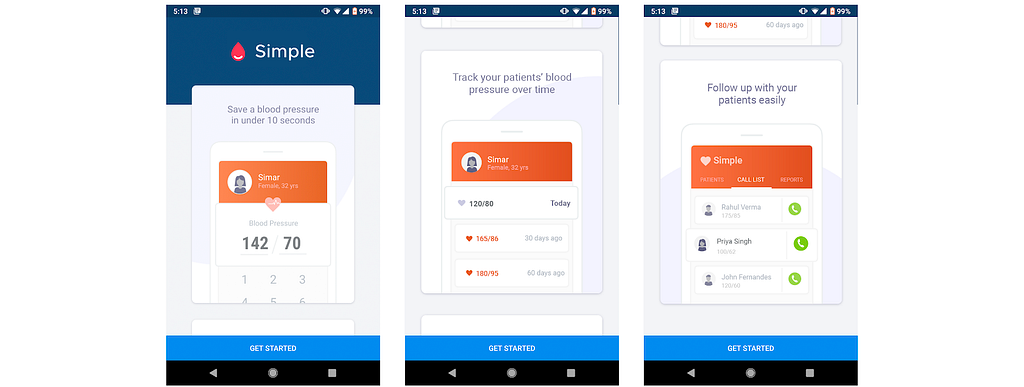
With an offline-first approach, apps like Simple are always snappy and responsive, so clinicians are never waiting while they treat patients.
Let me set the scene. A nurse named Ravdeep works in a busy clinic in a rural hospital in India. Patients are lined up outside her door in a chaotic line all of the way down the hall. Ravdeep is responsible for taking blood pressures and blood sugar measures for each patient. She quickly enters their data into the Simple app on her tablet, and sends them to the doctor if they appear to be hypertensive or diabetic.
This public hospital isn’t fancy, but you might be surprised to know that Ravdeep’s clinic has excellent 4G internet. In fact, much of India is covered with strong, affordable mobile networks. So, why would we choose to make an app like Simple using an offline-first approach?
Offline-first has several upsides, but the primary benefit is that the app is always snappy and responsive, so clinicians aren’t waiting for their app to talk to the cloud during patient interactions. In a busy clinic like Ravdeep’s, this is a crucial feature. In countries like India, Bangladesh, or Ethiopia where a patient encounter is often less than 5 minutes, every second counts and therefore every call to the server matters.
The big secondary benefit is that the app will work in the corners of India with limited internet. In a country as diverse as India, this is crucial.
What is offline-first?
A typical clinical app is in constant contact with a remote server, so each time patient data is updated it gets saved on the server. Designing an app offline-first is different because that data is saved locally on-device and is later “synced” or saved to a remote server. That means that the app will always be able to function with or without online internet. But, it also means that you need two databases with one on the device itself and one on the server and they must be kept in sync.
Pros
Works fast every time. Every second counts in a healthcare facility. Offline-first software is incredibly snappy. For us, this is the #1 benefit to going offline-first.
Works offline. The most obvious benefit of offline-first is that the app works when internet connectivity is low or really spotty. This gives Simple the flexibility to work in places where internet access is intermittent.
Works on a wide range of devices. The Android app is being used in public health facilities by users on their own personal devices. Having the ability to adjust how often we push and pull data allows us to optimize resources like battery, network usage, device storage, etc.
App continues to work without a central server. A user can continue using a fully-functional app without syncing with a central server if they wish to do so. This lets small private practitioners track the health of their patients without sharing their data, if they wish to do so.
Minimises the loss of data. Data is never lost even if our servers are unavailable. This gives us some breathing room during maintenance and upgrades.
Challenges
Sync is really hard. We constantly run into challenges with syncing. If the app doesn’t sync regularly enough to the server, nurses get confused and frustrated. But if we sync data too aggressively we can drain the nurse’s battery. Striking the right balance is tricky.
Doubles some of the work. As you can imagine, having two complete databases means a lot of back-end and front-end coordination and duplication of effort.
Multiple users in one facility. Inconsistent sync is a problem for one healthcare worker, but in team-based care it is even more problematic. The local database on each of the nurses’ phones is not consistent, and this can lead to confusion where one nurse will often see a different (more recently updated) view of the data.
Deleting data and resolving conflicts. With multiple users, it’s very possible to end up with data conflicts that must be resolved. For instance, one user edits a patient record but before she syncs data another user edits the same data on their device. It’s possible to resolve conflicts, but this adds to the complexity of the software.
Maintaining backwards compatibility. Making changes to the API can be very difficult. The API needs to work across many versions of the app, each of which have a slightly different understanding of how data is structured.
What we learned so far
The Simple app is being used in over 400 hospitals in India to manage over 190,000 patients with hypertension. We are constantly learning. Here are a few lessons we learned so far:
Physical BP Passports — the QR code contains a UUID
UUIDs are your friends Since the records are created on the mobile app and synced to server, we need an identifier that is easy to generate and is unique across all the devices. This makes UUIDs an ideal choice for our primary keys.
We also use UUIDs in our BP Passports (temporary identity cards issued to patients to easily find them in future visits). This allows us to print these cards from any location without fear of duplication.
The spec for UUID v3 allows us to deterministically generate new UUIDs based on a hash. Using this version, we can easily integrate data from external systems without having to maintain references in either of the databases.
Tracking time is really important In an offline first app, the changes made by a user may not be reflected on the server for a long time, which results in old changes overwriting newer ones. To prevent this, we track when the change was made on the mobile app and the time when the change was seen by the server. With both times we can determine and keep the relevant changes. This is also known as bi-temporal modelling and this blog post provides a nice introduction to the concept.
Limit what data gets synced When we started, every time a user registered with Simple we would sync all of the data from the server starting from the earliest record. This worked fine when we only had a few facilities, but as the number of patients in the database grew, we started facing two problems:
The user would have to download the entire dataset, a large part of which was irrelevant to the user. It is uncommon that a patient visits facilities in two different districts.
Syncing from the earliest record first would result in users waiting for an unknown amount of time to get all the patients in their facility.
To improve the user experience we now sync data only for facilities within their district and we sync data for the user’s own facility first. This reduces the initial load and lets the clinician to start recording her patients quickly.
Is offline-first worth the added effort?
Going offline-first was one of the best decisions we made in our technical architecture. When we watch a nurse in a busy outpatient department, it’s apparent how crucial performance is to her day. We have seen clinicians treating up to 200 patients in a single day — every extra second in a patient interaction at that velocity multiplies quickly.
Committing to offline-first also has opened up more deployment opportunities for Simple. In the next few months we will deploy to several locations where internet access is inconsistent. When our government partners asked if we could handle these environments, we could confidently say “yes!”
Simple is a free, open source, project through Resolve to Save Lives. If you are working on similar software and you have questions about our offline first approach, look at our code and documentation and get in touch with us. We’ll be happy to chat with you and explain in more detail what we’re doing. Thanks!
]]><![CDATA[Training, the Simple way]]>2019-10-04T00:00:00+00:00http://blog.nilenso.com/blog/2019/10/04/training-the-simple-wayWe experimented with several training methods: a short video combined with in-person support works best for us.
One year ago (in October 2018), we piloted the Simple app in five public health facilities in Punjab, India. The original process of teaching healthcare workers to use Simple in pilot hospitals involved in-person trainings from members of our team. We flew from Bangalore to Bathinda, spent a week visiting one facility each day, and taught healthcare workers how to use the app. We’ve come a long way since then.
Simple is now used in over four hundred health facilities in two states. Intensive in-person training is hard to scale, so we had to figure out how to make it easier.
Most other clinical software requires significant investment in training. One goal of Simple is to be able to get a healthcare worker up and running with minimal assistance, within an hour of installing the app. It’s a high bar, so we tried many approaches to explain Simple to our users.
In brief: A short, instructional training video with examples worked best by a long shot, but here are some other ideas we tried.
Tour on the home screen
Our first attempt at onboarding had a basic ‘tour’ with static, abstract screenshots of the functions of Simple.
First attempt at onboarding users
When our user tester Tanushree Jindal watched users trying the app for the first time, she observed that most users went straight for the “Get started” button, without scrolling through the screenshots that we had put together. Not great.
Paper training handbooks
We created a quick handbook that we could leave behind at in-person trainings. The handbook was pretty helpful, but keeping it updated was a challenge. Besides, they were not easily accessible unless we hand-delivered them.
Training manuals
Coach marks!
We then came up with the idea of using ‘coach marks’ to guide the user through the functions of the app. Maybe we could introduce each feature contextually to our users?
Coach marks to contextually introduce new features
We ran extensive usability tests with nurses and realised that there were simply too many coach marks to read. Coach marks were either ignored or got in the way. This didn’t work well either.
A simple video worked best
During field visits, we identified that a brief, engaging training video with demonstrations could have a lot of impact. So we quickly recorded a friendly video where we enacted the key activities in Simple. This worked really well during user tests and we learned:
Almost all healthcare workers watched the video
After 5 minutes, users became restless and lost interest
After watching the video, users could explain the app back to us
Nurses felt relatively confident that they could use the app after watching the training video
We edited the original video down to a crisp 5-minute film that showed a healthcare worker (me!) caring for a patient with hypertension at their clinic. This really hit home, as it was a very relatable setting for the primary users of our app.
We plan to make the recording available in multiple regional languages, so users can watch it in the language of their choice.
Where we are now
Today, the video is part of our short, in-app onboarding process for Simple. A nurse or a doctor can install the app from the Play Store, watch the training video as part of the registration flow, and learn how to use Simple.
The video is always available inside the app, within the built-in HELP section. One key benefit is that the video is nice, but not too fancy. As Simple evolves, we can easily replace it with an updated film that is more relevant.
Current onboarding flow
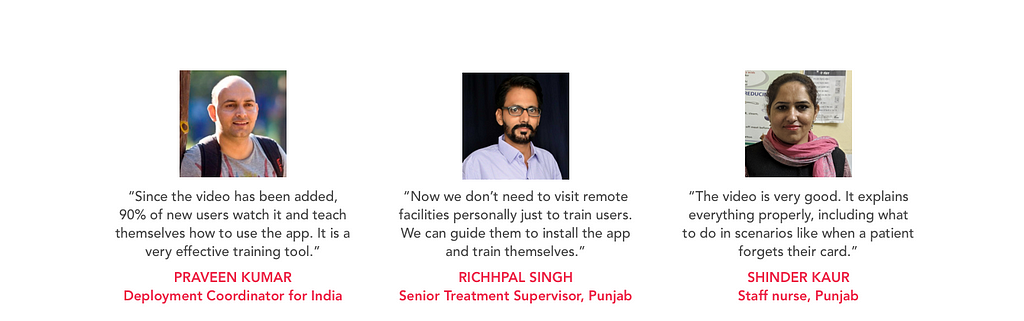
In addition to users, trainers have given us very positive feedback on the video, as it has proven to be a valuable tool for in-person trainings. Program managers, who go to the point of care to guide users on how the India Hypertension Control Initiative program should be implemented, play the video to demonstrate how Simple fits into the clinic workflows.
What trainers and users have to say about the video
What’s next?
Our takeaway from this exercise? Every mode of training had merits, but a contextual demonstration is a powerful tool that seems to hold a user’s attention. We have since recorded a few other videos that demonstrate specific flows in the app, and these have been received with equal enthusiasm.
The goal for the program is for it to eventually be entirely self-sufficient. We believe that by empowering users to teach themselves, we are taking the first important steps in that direction.
Credits
Thanks to Daniel Burka for scripting the first draft, and Anand Rama Krishnan for making us look good in the video. Also, thank you to Akshay Verma and Tanushree Jindal for user testing in the field. :)
Opening shot from the training video
<hr><p>Training, the Simple way was originally published in Simple on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>
]]><![CDATA[From wings to cups]]>2019-09-04T00:00:00+00:00http://blog.nilenso.com/blog/2019/09/04/from-wings-to-cupsI have been using Whisper winged sanitary napkins (also called pads) for as long as I can remember. Actually, always. I remember this really well. When it all began, I didn’t know there were alternatives. There was no one to talk about the alternatives. I learnt about tampons somewhere down the line, high school I think. But somehow that never made me change my mind.
I had gotten comfortable with my usage of pads.
I had always known (at least whole of my 20s) that using pads is ecologically damaging. I am regularly creating non-compostable, non-recyclable waste that is probably burnt or ends up in a landfill. But that is not what triggered me to make this change. It was the rashes, the irritation, the discomfort, and the smell.
It took me close to 10 months to make the switch. I bought my menstrual cup in September 2018. I started using it on and off. At first, my worry was leakage. I got over that in the first month by wearing a panty liner with the cup whenever I was worried. It took a couple of months, but eventually I stopped worrying about that and using liners. Then my worry was using it day to day, in office, in public spaces, specially emptying it or washing it in a public bathroom. Luckily, I am not a heavy bleeder and slowly I got used to using for a stretch of time without checking on it every few hours. And today finally, I am using it outside in an office space without giving it a second thought. It feels like an accomplishment, to be honest. No more unmanaged garbage, no more stealth black polybag or brown paper bag wrapped pad buying from middle aged men and women at pharmacies who think just a glimpse of the pad to the outside world can cause a natural disaster.
A lot of people I know got comfortable with a cup quite easily. One of the reasons I wanted to write to this is to say that it is okay to take your time. If it feels uncomfortable in the beginning, give it a little bit of time, try a different size maybe. Don’t get discouraged and chalk it up to “it is not my cup of tea”. Use it once in a while on your 3rd or 4th day when the flow is decreased. Practice cleaning it in the comfort of your home before you try wearing it outside. Read about other people’s experience or talk to them to see how they went about using it. It is definitely worth the effort, I can say that for sure.
I didn’t do a lot of research into choosing my cup. It was an impulse buy, really. I saw it in a storefront (not in India) and asked the lady in the store a couple of questions before buying it. But post buying it, I read a lot about how to use, how to choose etc before I started using it. I found the information on the Mooncup website(https://www.mooncup.co.uk/) really helpful. You can read that or even ask questions here and I will try to answer them as much as possible.
While I was transitioning from pads to cup, I started using Carmesi (https://mycarmesi.com/) instead of Whisper and that helped me a lot as it is all-natural, completely biodegradable sanitary pads. If you are unsure about the cup, and want to continue using pads — switch to Carmesi.
I have never written a post before so please pardon my writing. Yes, it can happen. I am 28, a software developer, and not a blogger. I just wanted to share this small little accomplishment in the hopes that it might inspire someone else out there to make the switch. Hope it does. :)
]]><![CDATA[India has a Three-Body Problem]]>2019-02-01T00:00:00+00:00http://blog.nilenso.com/blog/2019/02/01/india-has-a-three-body-problem
When I moved to Bangalore six years ago, I had no interest in India’s garbage management problem. I moved here to build a software company, not to muck about with garbage bins. But every time I would fly between the subcontinent and the Americas, I would find relief on my home continent and exhaustion on my continent of immigration. Living in a giant garbage heap is mentally taxing. Every moment spent outdoors is either an angsty mental rundown of how I might help, complete with acute feelings of powerlessness, or searching for someone to blame (my brain’s lazy personal favourite is a generic and completely unhelpful “the middle class”).
Reprieve comes in the form of resignation as the mind finally comes to accept a dangerous and unsustainable situation as inevitable. Telling yourself “this is just the way it is” at least allows you to enjoy a cup of tea or a single workday without obsessing about the garbage fire you will inevitably inhale on the bicycle ride home from the office.
But that doesn’t work for very long. The workday eventually ends and that bicycle ride inevitably happens. As you hold your breath and ride through the plume of smoke from a smouldering pile of trash on the side of the road, you ask yourself why in the sweet fuck do I even live here? And the answers instantly follow. Your friends are here, your home is here, your job is here. On the smallest scales some part of you belongs in India and on the largest possible scale you recognize that India’s problems of today are Earth’s problems of tomorrow. You can’t ignore them forever.
So you sit down and think about those problems. A lot.
What is garbage?
It may seem like a silly question but all sorts of variations have been asked of me over the years. “Why does garbage stink?” “Why can’t we just focus more attention on reuse?” and “Where do the costs of sanitation come from?” come to mind. If you’ve ever thrown something in the trash bin without asking yourself just where is this going to end up? you don’t really know what garbage is. The answer to this question changes with almost every piece of trash, with almost every bin, and definitely with every city.
Garbage is anything society’s majority decides it doesn’t want anymore. This extremely poisonous polystyrene Starbucks lid has served its purpose! I have a litre of burnt coffee in my stomach which means it’s definitely time to poop. Thanks for the assistance and off you go, immortal little lid, to know every worm that crawls by you until the sun of the milky way engulfs the Earth in five billion years and finally incinerates you. While this may be the future the majority plans, our little lid might never make it there. The lowest classes of human society repurpose garbage, sell garbage, and burn garbage to keep warm. The convenience of the healthy, educated elite are a disgrace to our species but, unexpectedly, the response of those at the bottom of the pyramid actually informs the way we should behave. This is because they know what garbage is.
Back in Canada, we don’t know what garbage is
One difficulty with living in a rich country backed by a huge resource economy is that it’s pretty easy to get self-righteous about how people in that country live, even if that way of life is far from perfect. It wasn’t that long ago that the garbage dump outside my hometown still burnt most of its garbage in open fires. (No one in southwest Saskatchewan bothers with that “landfill” euphemism.) It was on one of my many trips back and forth between India and Canada that it struck me how poorly we deal with waste in Canada.
Setting an example matters. If a country with the resources, time, money, and literacy of Canada can’t figure out what to do with our plastic bags or Styrofoam (Thermocol) it’s hard to imagine how any other country could do it. Canada leans on its unbelievable land mass and access to cheap fuel when it chooses to dump garbage in holes. As the world’s population distributes itself more evenly over the coming generations the sweep-it-under-the-rug approach will quickly bring the problems which plague India today to every other country on the planet. The problems of India today are the problems of Earth tomorrow.
Because Level 4 countries like Canada generally don’t appreciate garbage, Canada needs countries like India and China to show it the way. Canada has 3.7 crore (37 million) citizens; India has 134 crore (1.3 billion). Canada’s country-wide garbage solutions need to scale thirty six times over or they are a failure on a global scale.
Thankfully, India’s garbage crisis is a forcing function. Every day the garbage piles up inside and around India’s cities, the weight of it poisons us. Garbage on the street is an opportunity for the average citizen to stop and think about where her plastic milk packets go after they leave her house. Paradoxically, this is India’s opportunity to lead the rest of the globe.
Garbage is a small riddle
As an individual human being, there are only two steps to understanding our garbage. First, we need to deconstruct it. Second, we need to identify each component.
My friend’s question why does garbage stink? has an answer he could have puzzled out himself and it is arguably the first component of our deconstruction: some garbage is organic. Things we consume which were once alive are still alive on a microscopic level when they come to us. Living things stink. Or they will, eventually. The nice thing about this entire category is that every single item in it falls into the broad category of Organic. Biodegradable. Compost.
In India, biodegradable is often dubbed wet waste but I have issues with that nomenclature. It confuses people. A plastic tray with panipuri juice in it is certainly wet but it is in no way wet waste. If people understand that the green bin only means biodegradable, they’re less likely to throw plastic in there. Prior to our most recent train journey we took note of the waste signage in the Chennai Central railway station. The signage had other issues (which we’ll come to later) but the translations were on-point: biodegradable waste is सड़नशील कचरा in Hindi and… well, Preethi tells me those other words are the right ones in Tamil, whatever they say. The value of the word biodegradable is that it elevates the conversation. Are supposedly biodegradable plastics okay? Are coconut shells biodegradable enough, since they’re more like wood than food? The Wet Waste terminology doesn’t beg these questions.
Our second component comes from the other end of the biodegradability spectrum: plastics. The ubiquitous blue bin has come to mean recyclable material in general but it is plastic that stands apart from all other materials. No matter how many times you reuse that plastic bag, plastic chopstick, or plastic toy it will eventually have an end and that end should neither be the garbage dump nor a trash fire. Plastic needs to be recycled or broken down or we live with it forever.
The Three-Body Problem
This is where India gets stuck. There are many different methods of deconstruction and most of them don’t work. Any system which acknowledges the importance of our first two categories (organic and plastic) inherently creates a third: Everything Else.
This often stems from an enthusiasm to solve the garbage crisis. A city like Jaipur sees the problem of unsegregated waste and attacks it head-on… with the wrong weapon.
A garbage lorry in Jaipur
We recently visited the Jaipur Literature Festival and found ourselves pleasantly surprised by the city’s ubiquitous, segregated public waste system. Jaipur has segregated bins everywhere… but only blue and green bins and only blue and green garbage trucks. Blue/Green, Two-Body segregated bins are a step in the right direction. The citizens of Jaipur see these green and blue bins every day. Whether they respect the bins’ colours or not, a part of their subconscious starts to acknowledge that not all garbage is created equal.
A single look in these bins, however, will show you just how horribly ineffective a Two-Body system is. The green bin is full of dirty styrofoam plates. The blue bin is full of dirty, mixed waste. These broad, mutually exclusive strokes of Green = Wet Waste and Blue = Dry Waste mean that we must choose one of these two categories for Everything Else. A wet plastic dish full of panipuri juice is the least of our troubles. Where should I put a snot-filled tissue? A dirty diaper? Roadkill? Paint chips? Construction rubble? A used sanitary napkin?
Yeah. I don’t know, either. You need three bins.
This question of “other garbage” helped us persuade the building management of our Bangalore apartment complex to let us install a three-bin system: green for organic, blue for recyclables, red for everything else. “Everything else” is labelled reject on our bin but that’s just a fancy way of saying old-fashioned garbage. We actually encouraged our building-mates to put everything in the red bin until they were absolutely certain it belonged in the green or blue bin. A whole bin of clean compost is worthless if a single person poisons it. A whole bin of clean recycling is worthless if a single person dumps chutney all over it.
For months, before we were allowed to install the bins, the building manager repeatedly insisted that “a three-bin system will be too complicated” and “the municipal corporation waste-pickers don’t know what to do with three different bins.”
Over the years before Preethi and I installed these bins, we had heard every brand of argument against segregating garbage: it’s too complicated, the waste-pickers just throw it into one pile anyway, the system is corrupt, the residents / staff / citizens won’t follow the rules, and on and on and on. I’ve fought this battle so many times I’ve even codified my arguments for a Waste Maturity Model into a presentation. Thanks to battling these talking points with our families, friends, and coworkers, we were well-equipped to fend off the argument that the combination of a green and blue bin would be sufficient.
In the end, where does a diaper go? You need three bins.
Confusing your citizens in two easy steps!
On our way back from Jaipur to Chennai, we flew through Bangalore and it gave us a chance to see three different cities’ broken waste segregation messages.
Bangalore’s useless airport segregation completely flies in the face of the actual state guidelines
Bangalore actually has brilliant state-wide waste segregation guidelines, published in a dozen languages. They answer questions I wouldn’t think to ask (where do my coconut shells go?) and they are actually written into law.
Despite the law, the Bangalore International Airport thinks a 4-bin system is better than a 3-bin system. And, much to our chagrin, none of those bins is for reject garbage. Where do I put my snotty tissue in the Bangalore airport? Is a snotty tissue food, plastic, paper, or cans? None of the above. Hold onto it until you get to Chennai, I guess.
Chennai, on the other hand, has functional segregation at the airport. Hooray! For some unknown reason, they eschewed the standard international green/blue/black colours (or the slightly modified green/blue/red used in Karnataka). But that’s okay. At least I know where to dump my half-eaten dosa, the plastic spoon the chutney came with, and the wrapper with chocolate all over it that melted in my pocket during the flight.
Chennai airport has real waste segregation but the city has zero
Unfortunately, as soon as you get into the city the only bins you will find are for “non-recyclable waste” — giant green dumpsters akin to those of mid-twentieth-century American cities. If you want to figure out compost or recycling as a citizen of Chennai, you’re on your own.
Moving from one city to another can often be as drastic as moving from one country to another but moving from the airport to the office shouldn’t be. It’s little wonder that citizens are confused, waste-pickers are frustrated, and government officials feel overwhelmed.
India can lead. India must lead.
It is the perfect time for Indian states to unify on their understanding of the top three categories of waste. Whether we choose to label them wet, dry, and reject or organic, recyclable, and mixed or green, blue, and red or any other three titles, unity from the top will help us pick away at the many difficulties plaguing India’s streets and water bodies.
Over time, these three categories will spawn other categories. Separating plastics from paper from metal from glass from e-waste is a good way to split up the blue bin full of generic recyclables. If you want to split up the city’s plastic, there are at least seven plastic recycling symbols to go by. There are over forty international recycling symbols.
Baby steps, though. Keep the plastic out of the green bin and the chicken grease out of the blue bin. Then maybe we can discuss the road to Zero Waste.
Waste management is a form of project management. The project is massive, distributed, and constantly moving. It is global in scale and influenced by every single human being on Earth. Once it happens, successful waste management in India and China will be the gold standard for the rest of the globe.
These are the biggest projects. If we can do it here, we can do it anywhere.
India has a Three-Body Problem was originally published in Siggu on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]><![CDATA[Fast Sudoku Solver in Haskell #3: Picking the Right Data Structures]]>2018-08-13T00:00:00+00:00http://blog.nilenso.com/blog/2018/08/13/fast-sudoku-solver-in-haskell-3-picking-the-rightIn the previous part in this series of posts, we optimized the simple Sudoku solver by implementing a new strategy to prune cells, and were able to achieve a speedup of almost 200x. Afterwards, we profiled the solution and found that there were bottlenecks in the program, leading to a slowdown. In this post, we are going to follow the profiler and use the right Data Structures to improve the solution further and make it faster.
Sudoku is a number placement puzzle. It consists of a 9x9 grid which is to be filled with digits from 1 to 9 such that each row, each column and each of the nine 3x3 sub-grids contain all the digits. Some of the cells of the grid come pre-filled and the player has to fill the rest.
In the previous post, we improved the performance of the simple Sudoku solver by implementing a new strategy to prune cells. This new strategy found the digits which occurred uniquely, in pairs, or in triplets and fixed the cells to those digits. It led to a speedup of about 200x over our original naive solution. This is our current run1 time for solving all the 49151 17-clue puzzles:
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
258.97 real 257.34 user 1.52 sys
Instead of trying to guess how to improve the performance of our solution, let’s be methodical about it. We start with profiling the code to find the bottlenecks. Let’s compile and run the code with profiling flags:
This generates a sudoku.prof file with the profiling output. Here are the top seven Cost Centres3 from the file (cleaned for brevity):
Cost Centre
Src
%time
%alloc
exclusivePossibilities
Sudoku.hs:(49,1)-(62,26)
18.9
11.4
pruneCellsByFixed.pruneCell
Sudoku.hs:(75,5)-(76,36)
17.7
30.8
exclusivePossibilities.\.\
Sudoku.hs:55:38-70
11.7
20.3
fixM.\
Sudoku.hs:13:27-65
10.7
0.0
==
Sudoku.hs:15:56-57
5.6
0.0
pruneGrid'
Sudoku.hs:(103,1)-(106,64)
5.0
6.7
pruneCellsByFixed
Sudoku.hs:(71,1)-(76,36)
4.5
5.0
exclusivePossibilities.\
Sudoku.hs:58:36-68
3.4
2.5
Cost Centre points to a function, either named or anonymous. Src gives the line and column numbers of the source code of the function. %time and %alloc are the percentages of time spent and memory allocated in the function, respectively.
We see that exclusivePossibilities and the nested functions inside it take up almost 34% time of the entire run time. Second biggest bottleneck is the pruneCell function inside the pruneCellsByFixed function.
We are going to look at exclusivePossibilities later. For now, it is easy to guess the possible reason for pruneCell taking so much time. Here’s the code for reference:
pruneCellsByFixed :: [Cell] ->Maybe [Cell]pruneCellsByFixed cells =traverse pruneCell cellswhere fixeds = [x |Fixed x <- cells] pruneCell (Possible xs) = makeCell (xs Data.List.\\ fixeds) pruneCell x =Just x
pruneCell uses Data.List.\\ to find the difference of the cell’s possible digits and the fixed digits in the cell’s block. In Haskell, lists are implemented as singly linked lists. So, finding the difference or intersection of two lists is O(n2), that is, quadratic asymptotic complexity. Let’s tackle this bottleneck first.
A Set for All Occasions
What is a efficient data structure for finding differences and intersections? Why, a Set of course! A Set stores unique values and provides fast operations for testing membership of its elements. If we use a Set to represent the possible values of cells instead of a List, the program should run faster. Since the possible values are already unique (1–9), it should not break anything.
Haskell comes with a bunch of Set implementations:
Data.IntSet which is a specialized data structure for integer values, implemented as radix tree.
However, a much faster implementation is possible for our particular use-case. We can use a BitSet.
A BitSet uses bits to represent unique members of a Set. We map values to particular bits using some function. If the bit corresponding to a particular value is set to 1 then the value is present in the Set, else it is not. So, we need as many bits in a BitSet as the number of values in our domain, which makes is difficult to use for generic problems. But, for our Sudoku solver, we need to store only the digits 1–9 in the Set, which make BitSet very suitable for us. Also, the Set operations on BitSet are implemented using bit-level instructions in hardware, making them much faster than those on the other data structure listed above.
In Haskell, we can use the Data.Word module to represent a BitSet. Specifically, we can use the Data.Word.Word16 type which has sixteen bits because we need only nine bits to represent the nine digits. The bit-level operations on Word16 are provided by the Data.Bits module.
Bit by Bit, We Get Faster
First, we replace List with Word16 in the Cell type and add a helper function:
We set the same bits as the digits to indicate the presence of the digits in the possibilities. For example, for digit 1, we set the bit 1 so that the resulting Word16 is 0000 0000 0000 0010 or 2. This also means, for fixed cells, the value is count of the zeros from right.
The change in the exclusivePossibilities function is pretty minimal:
-exclusivePossibilities :: [Cell] -> [[Int]]+exclusivePossibilities :: [Cell] -> [Data.Word.Word16] exclusivePossibilities row = row & zip [1..9] & filter (isPossible . snd) & Data.List.foldl' (\acc ~(i, Possible xs) ->- Data.List.foldl'- (\acc' x -> Map.insertWith prepend x [i] acc')- acc- xs)+ Data.List.foldl'+ (\acc' x -> if Data.Bits.testBit xs x+ then Map.insertWith prepend x [i] acc'+ else acc')+ acc+ [1..9]) Map.empty & Map.filter ((< 4) . length) & Map.foldlWithKey' (\acc x is -> Map.insertWith prepend is [x] acc) Map.empty & Map.filterWithKey (\is xs -> length is == length xs) & Map.elems+ & map (Data.List.foldl' Data.Bits.setBit Data.Bits.zeroBits) where prepend ~[y] ys = y:ys
In the nested folding step, instead of folding over the possible values of the cells, now we fold over the digits from 1 to 9 and insert the entry in the map if the bit corresponding to the digit is set in the possibilities. And as the last step, we convert the exclusive possibilities to Word16 by folding them, starting with zero. As example in the REPL should be instructive:
Notice how the list difference and intersection functions are replaced by Data.Bits functions. Specifically, list difference is replace by bitwise-and of the bitwise-complement, and list intersection is replaced by bitwise-and.
We make a one-line change in the isGridInvalid function to find empty possible cells using bit ops:
isGridInvalid :: Grid -> Bool isGridInvalid grid = any isInvalidRow grid || any isInvalidRow (Data.List.transpose grid) || any isInvalidRow (subGridsToRows grid) where isInvalidRow row = let fixeds = [x | Fixed x <- row]- emptyPossibles = [x | Possible x <- row, null x]+ emptyPossibles = [() | Possible x <- row, x == Data.Bits.zeroBits] in hasDups fixeds || not (null emptyPossibles) hasDups l = hasDups' l [] hasDups' [] _ = False hasDups' (y:ys) xs | y `elem` xs = True | otherwise = hasDups' ys (y:xs)
And finally, we change the nextGrids functions to use bit operations:
nextGrids ::Grid-> (Grid, Grid)nextGrids grid =let (i, first@(Fixed _), rest) = fixCell. Data.List.minimumBy (compare`Data.Function.on` (possibilityCount .snd)).filter (isPossible .snd).zip [0..].concat$ gridin (replace2D i first grid, replace2D i rest grid)where possibilityCount (Possible xs) = Data.Bits.popCount xs possibilityCount (Fixed _) =1 fixCell ~(i, Possible xs) =let x = Data.Bits.countTrailingZeros xsincase makeCell (Data.Bits.clearBit xs x) ofNothing->error"Impossible case"Just cell -> (i, Fixed (Data.Bits.bit x), cell) replace2D ::Int-> a -> [[a]] -> [[a]] replace2D i v =let (x, y) = (i `quot`9, i `mod`9) in replace x (replace y (const v)) replace p f xs = [if i == p then f x else x | (x, i) <-zip xs [0..]]
possibilityCount now uses Data.Bits.popCount to count the number of bits set to 1. fixCell now chooses the first set bit from right as the digit to fix. Rest of the code stays the same. Let’s build and run it:
$ stack build
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
69.44 real 69.12 user 0.37 sys
Wow! That is almost 3.7x faster than the previous solution. It’s a massive win! But let’s not be content yet. To the profiler again!4
Back to the Profiler
Running the profiler again gives us these top six culprits:
Cost Centre
Src
%time
%alloc
exclusivePossibilities
Sudoku.hs:(57,1)-(74,26)
25.2
16.6
exclusivePossibilities.\.\
Sudoku.hs:64:23-96
19.0
32.8
fixM.\
Sudoku.hs:15:27-65
12.5
0.1
pruneCellsByFixed
Sudoku.hs:(83,1)-(88,36)
5.9
7.1
pruneGrid'
Sudoku.hs:(115,1)-(118,64)
5.0
8.6
Hurray! pruneCellsByFixed.pruneCell has disappeared from the list of top bottlenecks. Though exclusivePossibilities still remains here as expected.
exclusivePossibilities is a big function. The profiler does not really tell us which parts of it are the slow ones. That’s because by default, the profiler only considers functions as Cost Centres. We need to give it hints for it to be able to find bottlenecks inside functions. For that, we need to insert Cost Centre annotations in the code:
Here, {-# SCC "EP.zip" #-} is a Cost Centre annotation. "EP.zip" is the name we choose to give to this Cost Centre.
After profiling the code again, we get a different list of bottlenecks:
Cost Centre
Src
%time
%alloc
exclusivePossibilities.\.\
Sudoku.hs:(64,23)-(66,31)
19.5
31.4
fixM.\
Sudoku.hs:15:27-65
13.1
0.1
pruneCellsByFixed
Sudoku.hs:(85,1)-(90,36)
5.4
6.8
pruneGrid'
Sudoku.hs:(117,1)-(120,64)
4.8
8.3
EP.zip
Sudoku.hs:59:27-36
4.3
10.7
EP.Map.filter1
Sudoku.hs:70:35-61
4.2
0.5
chunksOf
Data/List/Split/Internals.hs:(514,1)-(517,49)
4.1
7.4
exclusivePossibilities.\
Sudoku.hs:71:64-96
4.0
3.4
EP.filter
Sudoku.hs:60:30-54
2.9
3.4
EP.foldl
Sudoku.hs:(61,29)-(69,15)
2.8
1.8
exclusivePossibilities
Sudoku.hs:(57,1)-(76,26)
2.7
1.9
chunksOf.splitter
Data/List/Split/Internals.hs:(516,3)-(517,49)
2.5
2.7
So almost one-fifth of the time is actually going in this nested one-line anonymous function inside exclusivePossibilities:
(\acc' n ->if Data.Bits.testBit xs n then Map.insertWith prepend n [i] acc' else acc')
But we are going to ignore it for now.
If we look closely, we also find that around 17% of the run time now goes into list traversal and manipulation. This is in the functions pruneCellsByFixed, pruneGrid', chunksOf and chunksOf.splitter, where the first two are majorly list traversal and transposition, and the last two are list splitting. Maybe it is time to get rid of lists altogether?
Vectors of Speed
Vector is a Haskell library for working with arrays. It implements very performant operations for integer-indexed array data. Unlike the lists in Haskell which are implemented as singly linked lists, vectors are stored in a contiguous set of memory locations. This makes random access to the elements a constant time operation. The memory overhead per additional item in vectors is also much smaller. Lists allocate memory for each item in the heap and have pointers to the memory locations in nodes, leading to a lot of wasted memory in holding pointers. On the other hand, operations on lists are lazy, whereas, operations on vectors are strict, and this may need to useless computation depending on the use-case5.
In our current code, we represent the grid as a list of lists of cells. All the pruning operations require us to traverse the grid list or the row lists. We also need to transform the grid back-and-forth for being able to use the same pruning operations for rows, columns and sub-grids. The pruning of cells and the choosing of pivot cells also requires us to replace cells in the grid with new ones, leading to a lot of list traversals.
To prevent all this linear-time list traversals, we can replace the nested list of lists with a single vector. Then all we need to do it to go over the right parts of this vector, looking up and replacing cells as needed. Since both lookups and updates on vectors are constant time, this should lead to a speedup.
Let’s start by changing the grid to a vector of cells.:
Since we plan to traverse different parts of the same vector, let’s define these different parts first:
typeCellIxs= [Int]fromXY :: (Int, Int) ->IntfromXY (x, y) = x *9+ yallRowIxs, allColIxs, allSubGridIxs :: [CellIxs]allRowIxs = [getRow i | i <- [0..8]]where getRow n = [ fromXY (n, i) | i <- [0..8] ]allColIxs = [getCol i | i <- [0..8]]where getCol n = [ fromXY (i, n) | i <- [0..8] ]allSubGridIxs = [getSubGrid i | i <- [0..8]]where getSubGrid n =let (r, c) = (n `quot`3, n `mod`3)in [ fromXY (3* r + i, 3* c + j) | i <- [0..2], j <- [0..2] ]
We define a type for cell indices as a list of integers. Then we create three lists of cell indices: all row indices, all column indices, and all sub-grid indices. Let’s check these out in the REPL:
We can verify manually that these indices are correct.
Read and show functions are easy to change for vector:
readGrid :: String -> Maybe Grid readGrid s- | length s == 81 = traverse (traverse readCell) . Data.List.Split.chunksOf 9 $ s+ | length s == 81 = Data.Vector.fromList <$> traverse readCell s | otherwise = Nothing where allBitsSet = 1022 readCell '.' = Just $ Possible allBitsSet readCell c | Data.Char.isDigit c && c > '0' = Just . Fixed . Data.Bits.bit . Data.Char.digitToInt $ c | otherwise = Nothing showGrid :: Grid -> String-showGrid = unlines . map (unwords . map showCell)+showGrid grid =+ unlines . map (unwords . map (showCell . (grid !))) $ allRowIxs where showCell (Fixed x) = show . Data.Bits.countTrailingZeros $ x showCell _ = "." showGridWithPossibilities :: Grid -> String-showGridWithPossibilities = unlines . map (unwords . map showCell)+showGridWithPossibilities grid =+ unlines . map (unwords . map (showCell . (grid !))) $ allRowIxs where showCell (Fixed x) = (show . Data.Bits.countTrailingZeros $ x) ++ " " showCell (Possible xs) = "[" ++ map (\i -> if Data.Bits.testBit xs i then Data.Char.intToDigit i else ' ') [1..9] ++ "]"
readGrid simply changes to work on a single vector of cells instead of a list of lists. Show functions have a pretty minor change to do lookups from a vector using the row indices and the (!) function. The (!) function is the vector indexing function which is similar to the (!!) function, except it executes in constant time.
The pruning related functions are rewritten for working with vectors:
replaceCell ::Int->Cell->Grid->GridreplaceCell i c g = g Data.Vector.// [(i, c)]pruneCellsByFixed ::Grid->CellIxs->MaybeGridpruneCellsByFixed grid cellIxs = Control.Monad.foldM pruneCell grid .map (\i -> (i, grid ! i)) $ cellIxswhere fixeds = setBits Data.Bits.zeroBits [x |Fixed x <-map (grid !) cellIxs] pruneCell g (_, Fixed _) =Just g pruneCell g (i, Possible xs)| xs' == xs =Just g|otherwise=flip (replaceCell i) g <$> makeCell xs'where xs' = xs Data.Bits..&. Data.Bits.complement fixedspruneCellsByExclusives ::Grid->CellIxs->MaybeGridpruneCellsByExclusives grid cellIxs =case exclusives of [] ->Just grid _ -> Control.Monad.foldM pruneCell grid .zip cellIxs $ cellswhere cells =map (grid !) cellIxs exclusives = exclusivePossibilities cells allExclusives = setBits Data.Bits.zeroBits exclusives pruneCell g (_, Fixed _) =Just g pruneCell g (i, Possible xs)| intersection == xs =Just g| intersection `elem` exclusives =flip (replaceCell i) g <$> makeCell intersection|otherwise=Just gwhere intersection = xs Data.Bits..&. allExclusivespruneCells ::Grid->CellIxs->MaybeGridpruneCells grid cellIxs = fixM (flip pruneCellsByFixed cellIxs) grid>>= fixM (flip pruneCellsByExclusives cellIxs)
All the three functions now take the grid and the cell indices instead of a list of cells, and use the cell indices to lookup the cells from the grid. Also, instead of using the traverse function as earlier, now we use the Control.Monad.foldM function to fold over the cell-index-and-cell tuples in the context of the Maybe monad, making changes to the grid directly.
We use the replaceCell function to replace cells at an index in the grid. It is a simple wrapper over the vector update function Data.Vector.//. Rest of the code is same in essence, except a few changes to accommodate the changed function parameters.
pruneGrid' function does not need to do transpositions and back-transpositions anymore as now we use the cell indices to go over the right parts of the grid vector directly:
Notice that the traverse function here is also replaced by the Control.Monad.foldM function.
Similarly, the grid predicate functions change a little to go over a vector instead of a list of lists:
isGridFilled :: Grid -> Bool-isGridFilled grid = null [ () | Possible _ <- concat grid ]+isGridFilled = not . Data.Vector.any isPossible isGridInvalid :: Grid -> Bool isGridInvalid grid =- any isInvalidRow grid- || any isInvalidRow (Data.List.transpose grid)- || any isInvalidRow (subGridsToRows grid)+ any isInvalidRow (map (map (grid !)) allRowIxs)+ || any isInvalidRow (map (map (grid !)) allColIxs)+ || any isInvalidRow (map (map (grid !)) allSubGridIxs)
And finally, we change the nextGrids function to replace the list related operations with the vector related ones:
nextGrids :: Grid -> (Grid, Grid) nextGrids grid = let (i, first@(Fixed _), rest) = fixCell- . Data.List.minimumBy+ . Data.Vector.minimumBy (compare `Data.Function.on` (possibilityCount . snd))- . filter (isPossible . snd)- . zip [0..]- . concat+ . Data.Vector.imapMaybe+ (\j cell -> if isPossible cell then Just (j, cell) else Nothing) $ grid- in (replace2D i first grid, replace2D i rest grid)+ in (replaceCell i first grid, replaceCell i rest grid)
We also switch the replace2D function which went over the entire list of lists of cells to replace a cell, with the vector-based replaceCell function.
All the required changes are done. Let’s do a run:
$ stack build
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
88.53 real 88.16 user 0.41 sys
Oops! Instead of getting a speedup, our vector-based code is actually 1.3x slower than the list-based code. How did this happen? Time to bust out the profiler again!
Revenge of the (==)
Profiling the current code gives us the following hotspots:
Cost Centre
Src
%time
%alloc
>>=
Data/Vector/Fusion/Util.hs:36:3-18
52.2
51.0
basicUnsafeIndexM
Data/Vector.hs:278:3-62
22.2
20.4
exclusivePossibilities
Sudoku.hs:(75,1)-(93,26)
6.8
8.3
exclusivePossibilities.\.\
Sudoku.hs:83:23-96
3.8
8.8
pruneCellsByFixed.fixeds
Sudoku.hs:105:5-77
2.0
1.7
We see a sudden appearance of (>>=) from the Data.Vector.Fusion.Util module at the top of the list, taking more than half of the run time. For more clues, we dive into the detailed profiler report and find this bit:
Cost Centre
Src
%time
%alloc
pruneGrid
Sudoku.hs:143:1-27
0.0
0.0
fixM
Sudoku.hs:16:1-65
0.1
0.0
fixM.\
Sudoku.hs:16:27-65
0.2
0.1
==
Data/Vector.hs:287:3-50
1.0
1.4
>>=
Data/Vector/Fusion/Util.hs:36:3-18
51.9
50.7
basicUnsafeIndexM
Data/Vector.hs:278:3-62
19.3
20.3
Here, the indentation indicated nesting of operations. We see that both the (>>=) and basicUnsafeIndexM functions — which together take around three-quarter of the run time — are being called from the (==) function in the fixM function6. It seems like we are checking for equality too many times. Here’s the usage of the fixM for reference:
In pruneGrid, we run pruneGrid' till the resultant grid settles, that is, the grid computed in a particular iteration is equal to the grid in the previous iteration. Interestingly, we do the same thing in pruneCells too. We equate the whole grid to check for settling of each block of cells. This is the reason of the slowdown.
One Function to Prune Them All
Why did we add fixM in the pruneCells function at all? Quoting from the previous post,
We need to run pruneCellsByFixed and pruneCellsByExclusives repeatedly using fixM because an unsettled row can lead to wrong solutions.
Imagine a row which just got a 9 fixed because of pruneCellsByFixed. If we don’t run the function again, the row may be left with one non-fixed cell with a 9. When we run this row through pruneCellsByExclusives, it’ll consider the 9 in the non-fixed cell as a Single and fix it. This will lead to two 9s in the same row, causing the solution to fail.
So the reason we added fixM is that, we run the two pruning strategies one-after-another. That way, they see the cells in the same block in different states. If we were to merge the two pruning functions into a single one such that they work in lockstep, we would not need to run fixM at all!
With this idea, we rewrite pruneCells as a single function:
pruneCells ::Grid->CellIxs->MaybeGridpruneCells grid cellIxs = Control.Monad.foldM pruneCell grid cellIxswhere cells =map (grid !) cellIxs exclusives = exclusivePossibilities cells allExclusives = setBits Data.Bits.zeroBits exclusives fixeds = setBits Data.Bits.zeroBits [x |Fixed x <- cells] pruneCell g i = pruneCellByFixed g (i, g ! i) >>= \g' -> pruneCellByExclusives g' (i, g' ! i) pruneCellByFixed g (_, Fixed _) =Just g pruneCellByFixed g (i, Possible xs)| xs' == xs =Just g|otherwise=flip (replaceCell i) g <$> makeCell xs'where xs' = xs Data.Bits..&. Data.Bits.complement fixeds pruneCellByExclusives g (_, Fixed _) =Just g pruneCellByExclusives g (i, Possible xs)|null exclusives =Just g| intersection == xs =Just g| intersection `elem` exclusives =flip (replaceCell i) g <$> makeCell intersection|otherwise=Just gwhere intersection = xs Data.Bits..&. allExclusives
We have merged the two pruning functions almost blindly. The important part here is the nested pruneCell function which uses monadic bind (>>=) to ensure that cells fixed in the first step are seen by the next step. Merging the two functions ensures that both strategies will see same Exclusives and Fixeds, thereby running in lockstep.
Let’s try it out:
$ stack build
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
57.67 real 57.12 user 0.46 sys
Ah, now it’s faster than the list-based implementation by 1.2x7. Let’s see what the profiler says:
Cost Centre
Src
%time
%alloc
exclusivePossibilities.\.\
Sudoku.hs:82:23-96
15.7
33.3
pruneCells
Sudoku.hs:(101,1)-(126,53)
9.6
6.8
pruneCells.pruneCell
Sudoku.hs:(108,5)-(109,83)
9.5
2.1
basicUnsafeIndexM
Data/Vector.hs:278:3-62
9.4
0.5
pruneCells.pruneCell.\
Sudoku.hs:109:48-83
7.6
2.1
pruneCells.cells
Sudoku.hs:103:5-40
7.1
10.9
exclusivePossibilities.\
Sudoku.hs:87:64-96
3.5
3.8
EP.Map.filter1
Sudoku.hs:86:35-61
3.0
0.6
>>=
Data/Vector/Fusion/Util.hs:36:3-18
2.8
2.0
replaceCell
Sudoku.hs:59:1-45
2.5
1.1
EP.filter
Sudoku.hs:78:30-54
2.4
3.3
primitive
Control/Monad/Primitive.hs:195:3-16
2.3
6.5
The double nested anonymous function mentioned before is still the biggest culprit but fixM has disappeared from the list. Let’s tackle exclusivePossibilities now.
Rise of the Mutables
Here’s exclusivePossibilities again for reference:
exclusivePossibilities :: [Cell] -> [Data.Word.Word16]exclusivePossibilities row = row&zip [1..9]&filter (isPossible .snd)& Data.List.foldl' (\acc ~(i, Possible xs) -> Data.List.foldl' (\acc' n ->if Data.Bits.testBit xs n then Map.insertWith prepend n [i] acc' else acc') acc [1..9]) Map.empty& Map.filter ((<4) .length)& Map.foldlWithKey'(\acc x is -> Map.insertWith prepend is [x] acc) Map.empty& Map.filterWithKey (\is xs ->length is ==length xs)& Map.elems&map (Data.List.foldl' Data.Bits.setBit Data.Bits.zeroBits)where prepend ~[y] ys = y:ys
Let’s zoom into lines 6–14. Here, we do a fold with a nested fold over the non-fixed cells of the given block to accumulate the mapping from the digits to the indices of the cells they occur in. We use a Data.Map.Strict map as the accumulator. If a digit is not present in the map as a key then we add a singleton list containing the corresponding cell index as the value. If the digit is already present in the map then we prepend the cell index to the list of indices for the digit. So we end up “mutating” the map repeatedly.
Of course, it’s not actual mutation because the map data structure we are using is immutable. Each change to the map instance creates a new copy with the addition, which we thread through the fold operation, and we get the final copy at the end. This may be the reason of the slowness in this section of the code.
What if, instead of using an immutable data structure for this, we used a mutable one? But how can we do that when we know that Haskell is a pure language? Purity means that all code must be referentially transparent, and mutability certainly isn’t. It turns out, there is an escape hatch to mutability in Haskell. Quoting the relevant section from the book Real World Haskell:
Haskell provides a special monad, named ST, which lets us work safely with mutable state. Compared to the State monad, it has some powerful added capabilities.
We can thaw an immutable array to give a mutable array; modify the mutable array in place; and freeze a new immutable array when we are done.
We have the ability to use mutable references. This lets us implement data structures that we can modify after construction, as in an imperative language. This ability is vital for some imperative data structures and algorithms, for which similarly efficient purely functional alternatives have not yet been discovered.
So if we use a mutable map in the ST monad, we may be able to get rid of this bottleneck. But, we can actually do better! Since the keys of our map are digits 1–9, we can use a mutable vector to store the indices. In fact, we can go one step even further and store the indices as a BitSet as Word16 because they also range from 1 to 9, and are unique for a block. This lets us use an unboxed mutable vector. What is unboxing you ask? Quoting from the GHC docs:
Most types in GHC are boxed, which means that values of that type are represented by a pointer to a heap object. The representation of a Haskell Int, for example, is a two-word heap object. An unboxed type, however, is represented by the value itself, no pointers or heap allocation are involved.
When combined with vector, unboxing of values means the whole vector is stored as single byte array, avoiding pointer redirections completely. This is more memory efficient and allows better usage of caches8. Let’s rewrite exclusivePossibilities using ST and unboxed mutable vectors.
First we write the core of this operation, the function cellIndicesList which take a list of cells and returns the digit to cell indices mapping. The mapping is returned as a list. The zeroth value in this list is the indices of the cells which have 1 as a possible digit, and so on. The indices themselves are packed as BitSets. If the bit 1 is set then the first cell has a particular digit. Let’s say it returns [0,688,54,134,0,654,652,526,670]. In 10-bit binary it is:
If the value of the intersection of a particular digit and a particular cell index in the table is set to 1, then the digit is a possibility in the cell, else it is not. Here’s the code:
The whole mutable code runs inside the runST function. runST take an operation in ST monad and executes it, making sure that the mutable references created inside it cannot escape the scope of runST. This is done using a type-system trickery called Rank-2 types.
Inside the ST operation, we start with creating a mutable vector of Word16s of size 9 with all its values initially set to zero. We also initialize a mutable reference to keep track of the cell index we are on. Then we run two nested for loops, going over each cell and each digit 1–9, setting the right bit of the right index of the mutable vector. During this, we mutate the vector directly using the Data.Vector.Unboxed.Mutable.unsafeModify function. At the end of the ST operation, we freeze the mutable vector to return an immutable version of it. Outside runST, we convert the immutable vector to a list. Notice how this code is quite similar to how we’d write it in imperative programming languages like C or Java9.
It is easy to use this function now to rewrite exclusivePossibilities:
exclusivePossibilities :: [Cell] -> [Data.Word.Word16] exclusivePossibilities row = row- & zip [1..9]- & filter (isPossible . snd)- & Data.List.foldl'- (\acc ~(i, Possible xs) ->- Data.List.foldl'- (\acc' n -> if Data.Bits.testBit xs n - then Map.insertWith prepend n [i] acc' - else acc')- acc- [1..9])- Map.empty+ & cellIndicesList+ & zip [1..9]- & Map.filter ((< 4) . length)- & Map.foldlWithKey' (\acc x is -> Map.insertWith prepend is [x] acc) Map.empty- & Map.filterWithKey (\is xs -> length is == length xs)+ & filter (\(_, is) -> let p = Data.Bits.popCount is in p > 0 && p < 4)+ & Data.List.foldl' (\acc (x, is) -> Map.insertWith prepend is [x] acc) Map.empty+ & Map.filterWithKey (\is xs -> Data.Bits.popCount is == length xs) & Map.elems & map (Data.List.foldl' Data.Bits.setBit Data.Bits.zeroBits) where prepend ~[y] ys = y:ys
We replace the nested two-fold operation with cellIndicesList. Then we replace some map related function with the corresponding list ones because cellIndicesList returns a list. We also replace the length function call on cell indices with Data.Bits.popCount function call as the indices are represented as Word16 now.
That is it. Let’s build and run it now:
$ stack build
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
35.04 real 34.84 user 0.24 sys
That’s a 1.6x speedup over the map-and-fold based version. Let’s check what the profiler has to say:
Cost Centre
Src
%time
%alloc
cellIndicesList.\.\
Sudoku.hs:(88,11)-(89,81)
10.7
6.0
primitive
Control/Monad/Primitive.hs:195:3-16
7.9
6.9
pruneCells
Sudoku.hs:(113,1)-(138,53)
7.5
6.4
cellIndicesList
Sudoku.hs:(79,1)-(91,40)
7.4
10.1
basicUnsafeIndexM
Data/Vector.hs:278:3-62
7.3
0.5
pruneCells.pruneCell
Sudoku.hs:(120,5)-(121,83)
6.8
2.0
exclusivePossibilities
Sudoku.hs:(94,1)-(104,26)
6.5
9.7
pruneCells.pruneCell.\
Sudoku.hs:121:48-83
6.1
2.0
cellIndicesList.\
Sudoku.hs:(83,42)-(90,37)
5.5
3.5
pruneCells.cells
Sudoku.hs:115:5-40
5.0
10.4
The run time is spread quite evenly over all the functions now and there are no hotspots anymore. We stop optimizating at this point10. Let’s see how far we have come up.
Comparison of Implementations
Below is a table showing the speedups we got with each new implementation:
Implementation
Run Time (s)
Incremental Speedup
Cumulative Speedup
Simple
47450
1x
1x
Exclusive Pruning
258.97
183.23x
183x
BitSet
69.44
3.73x
683x
Vector
57.67
1.20x
823x
Mutable Vector
35.04
1.65x
1354x
The first improvement over the simple solution got us the most major speedup of 183x. After that, we followed the profiler, fixing bottlenecks by using the right data structures. We got quite significant speedup over the naive list-based solution, leading to drop in the run time from 259 seconds to 35 seconds. In total, we have done more than a thousand times improvement in the run time since the first solution!
Conclusion
In this post, we improved upon our list-based Sudoku solution from the last time. We profiled the code at each step, found the bottlenecks and fixed them by choosing the right data structure for the case. We ended up using BitSets and Vectors — both immutable and mutable varieties — for the different parts of the code. Finally, we sped up our program by 7.4 times. Can we go even faster? How about using all those other CPU cores which have been lying idle? Come back for the next post in this series where we’ll explore the parallel programming facilities in Haskell. The code till now is available here. Discuss this post on r/haskell or leave a comment.
All the runs were done on my MacBook Pro from 2014 with 2.2 GHz Intel Core i7 CPU and 16 GB memory.↩︎
A lot of the code in this post references the code from the previous posts, including showing diffs. So, please read the previous posts if you have not already done so.↩︎
Notice the British English spelling of the word “Centre”. GHC was originally developed in University of Glasgow in Scotland.↩︎
The code for the BitSet based implementation can be found here.↩︎
This article on School of Haskell goes into details about performance of vectors vs. lists. There are also these benchmarks for sequence data structures in Haskell: lists, vectors, seqs, etc.↩︎
We see Haskell’s laziness at work here. In the code for the fixM function, the (==) function is nested inside the (>>=) function, but because of laziness, they are actually evaluated in the reverse order. The evaluation of parameters for the (==) function causes the (>>=) function to be evaluated.↩︎
The code for the vector based implementation can be found here.↩︎
Unboxed vectors have some restrictions on the kind of values that can be put into them but Word16 already follows those restrictions so we are good.↩︎
Haskell can be a pretty good imperative programming language using the ST monad. This article shows how to implement some algorithms which require mutable data structures in Haskell.↩︎
The code for the mutable vector based implementation can be found here.↩︎
]]><![CDATA[Fast Sudoku Solver in Haskell #2: A 200x Faster Solution]]>2018-07-11T00:00:00+00:00http://blog.nilenso.com/blog/2018/07/11/fast-sudoku-solver-in-haskell-2-a-200x-faster-solIn the first part of this series of posts, we wrote a simple Sudoku solver in Haskell. It used a constraint satisfaction algorithm with backtracking. The solution worked well but was very slow. In this post, we are going to improve it and make it fast.
Sudoku is a number placement puzzle. It consists of a 9x9 grid which is to be filled with digits from 1 to 9 such that each row, each column and each of the nine 3x3 sub-grids contain all the digits. Some of the cells of the grid come pre-filled and the player has to fill the rest.
In the previous post, we implemented a simple Sudoku solver without paying much attention to its performance characteristics. We ran1 some of 17-clue puzzles2 through our program to see how fast it was:
$ head -n100 sudoku17.txt | time stack exec sudoku
... output omitted ...
116.70 real 198.09 user 94.46 sys
So, it took about 117 seconds to solve one hundred puzzles. At this speed, it would take about 16 hours to solve all the 49151 puzzles contained in the file. This is way too slow. We need to find ways to make it faster. Let’s go back to the drawing board.
Constraints and Corollaries
In a Sudoku puzzle, we have a partially filled 9x9 grid which we have to fill completely while following the constraints of the game.
Earlier, we followed a simple pruning algorithm which removed all the solved (or fixed) digits from neighbours of the fixed cells. We repeated the pruning till the fixed and non-fixed values in the grid stopped changing (or the grid settled). Here’s an example of a grid before pruning:
We see how the possibilities conflicting with the fixed values are removed. We also see how some of the non-fixed cells turn into fixed ones as all their other possible values get eliminated.
This simple strategy follows directly from the constraints of Sudoku. But, are there more complex strategies which are implied indirectly?
Singles, Twins and Triplets
Let’s have a look at this sample row captured from a solution in progress:
Notice how the sixth cell is the only one with 1 as a possibility in it. It is obvious that we should fix the sixth cell to 1 as we cannot place 1 in any other cell in the row. Let’s call this the Singles3 scenario.
But, our current solution will not fix the sixth cell to 1 till one of these cases arise:
all other possibilities of the cell are pruned away, or,
the cell is chosen as pivot in the nextGrids function and 1 is chosen as the value to fix.
This may take very long and lead to a longer solution time. Let’s assume that we recognize the Singles scenario while pruning cells and fix the cell to 1 right then. That would cut down the search tree by a lot and make the solution much faster.
It turns out, we can generalize this pattern. Let’s check out this sample row from middle of a solution:
It is a bit difficult to notice with the naked eye but there’s something special here too. The digits 5 and 7 occur only in the third and the ninth cells. Though they are accompanied by other digits in those cells, they are not present in any other cells. This means, we can place 5 and 7 either in the third or the ninth cell and no other cells. This implies that we can prune the third and ninth cells to have only 5 and 7 like this:
This is the Twins scenario. As we can imagine, this pattern extends to groups of three digits and beyond. When three digits can be found only in three cells in a block, it is the Triplets scenario, as in the example below:
Let’s call these three scenarios Exclusives in general.
We can extend this to Quadruplets scenario and further. But such scenarios occur rarely in a 9x9 Sudoku puzzle. Trying to find them may end up being more computationally expensive than the benefit we may get in solution time speedup by finding them.
Now that we have discovered these new strategies to prune cells, let’s implement them in Haskell.
A Little Forward, a Little Backward
We can implement the three new strategies to prune cells as one function for each. However, we can actually implement all these strategies in a single function. But, this function is a bit more complex than the previous pruning function. So first, let’s try to understand its working using tables. Let’s take this sample row:
We extract the isPossible function to the top level from the nextGrids function for reuse. Then we write the exclusivePossibilities function which finds the Exclusives in the input row. This function is written using the reverse application operator (&)4 instead of the usual ($) operator so that we can read it from top to bottom. We also show the intermediate values for a sample input after every step in the function chain.
The nub of the function lies in step 3 (pun intended). We do a nested fold over all the non-fixed cells and all the possible digits in them to compute the map5 which represents the first table. Thereafter, we filter the map to keep only the entries with length less than four (step 4). Then we flip it to create a new map which represents the second table (step 5). Finally, we filter the flipped map for the entries where the cell count is same as the digit count (step 6) to arrive at the final table. The step 7 just gets the values in the map which is the list of all the Exclusives in the input row.
Pruning the Cells, Exclusively
To start with, we extract some reusable code from the previous pruneCells function and rename it to pruneCellsByFixed:
makeCell :: [Int] ->MaybeCellmakeCell ys =case ys of [] ->Nothing [y] ->Just$Fixed y _ ->Just$Possible yspruneCellsByFixed :: [Cell] ->Maybe [Cell]pruneCellsByFixed cells =traverse pruneCell cellswhere fixeds = [x |Fixed x <- cells] pruneCell (Possible xs) = makeCell (xs Data.List.\\ fixeds) pruneCell x =Just x
Now we write the pruneCellsByExclusives function which uses the exclusivePossibilities function to prune the cells:
pruneCellsByExclusives works exactly as shown in the examples above. We first find the list of Exclusives in the given cells. If there are no Exclusives, there’s nothing to do and we just return the cells. If we find any Exclusives, we traverse the cells, pruning each cell to only the intersection of the possible digits in the cell and Exclusive digits. That’s it! We reuse the makeCell function to create a new cell with the intersection.
As the final step, we rewrite the pruneCells function by combining both the functions.
fixM :: (Eq t, Monad m) => (t -> m t) -> t -> m tfixM f x = f x >>= \x' ->if x' == x thenreturn x else fixM f x'pruneCells :: [Cell] ->Maybe [Cell]pruneCells cells = fixM pruneCellsByFixed cells >>= fixM pruneCellsByExclusives
We have extracted fixM as a top level function from the pruneGrid function. Just like the pruneGrid' function, we need to use monadic bind (>>=) to chain the two pruning steps. We also use fixM to apply each step repeatedly till the pruned cells settle6.
No further code changes are required. It is time to check out the improvements.
Faster than a Speeding Bullet!
Let’s build the program and run the exact same number of puzzles as before:
$ head -n100 sudoku17.txt | time stack exec sudoku
... output omitted ...
0.53 real 0.58 user 0.23 sys
Woah! It is way faster than before. Let’s solve all the puzzles now:
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
282.98 real 407.25 user 109.27 sys
So it is took about 283 seconds to solve all the 49151 puzzles. The speedup is about 200x7. That’s about 5.8 milliseconds per puzzle.
Let’s do a quick profiling to see where the time is going:
This generates a file named sudoku.prof with the profiling results. Here are the top five most time-taking functions (cleaned for brevity):
Cost Center
Source
%time
%alloc
exclusivePossibilities
(49,1)-(62,26)
17.6
11.4
pruneCellsByFixed.pruneCell
(75,5)-(76,36)
16.9
30.8
exclusivePossibilities.\.\
55:38-70
12.2
20.3
fixM.\
13:27-65
10.0
0.0
==
15:56-57
7.2
0.0
Looking at the report, my guess is that a lot of time is going into list operations. Lists are known to be inefficient in Haskell so maybe we should switch to some other data structures?
Update
As per the comment below by Chris Casinghino, I ran both the versions of code without the -threaded, -rtsopts and -with-rtsopts=-N options. The time for previous post’s code:
$ head -n100 sudoku17.txt | time stack exec sudoku
... output omitted ...
96.54 real 95.90 user 0.66 sys
And the time for this post’s code:
$ cat sudoku17.txt | time stack exec sudoku > /dev/null
258.97 real 257.34 user 1.52 sys
So, both the versions run about 10% faster without the threading options. I suspect this has something to do with GHC’s parallel GC as described in this post. So for now, I’ll keep threading disabled.
Conclusion
In this post, we improved upon our simple Sudoku solution from the last time. We discovered and implemented a new strategy to prune cells, and we achieved a 200x speedup. But profiling shows that we still have many possibilities for improvements. We’ll work on that and more in the upcoming posts in this series. The code till now is available here. Discuss this post on r/haskell or leave a comment.
All the runs were done on my MacBook Pro from 2014 with 2.2 GHz Intel Core i7 CPU and 16 GB memory.↩︎
At least 17 cells must be pre-filled in a Sudoku puzzle for it to have a unique solution. So 17-clue puzzles are the most difficult of all puzzles. This paper by McGuire, Tugemann and Civario gives the proof of the same.↩︎
Reverse application operation is not used much in Haskell. But it is the preferred way of function chaining in some other functional programming languages like Clojure, FSharp, and Elixir.↩︎
We need to run pruneCellsByFixed and pruneCellsByExclusives repeatedly using fixM because an unsettled row can lead to wrong solutions.
Imagine a row which just got a 9 fixed because of pruneCellsByFixed. If we don’t run the function again, the row may be left with one non-fixed cell with a 9. When we run this row through pruneCellsByExclusives, it’ll consider the 9 in the non-fixed cell as a Single and fix it. This will lead to two 9s in the same row, causing the solution to fail.↩︎
]]><![CDATA[Fast Sudoku Solver in Haskell #1: A Simple Solution]]>2018-06-28T00:00:00+00:00http://blog.nilenso.com/blog/2018/06/28/fast-sudoku-solver-in-haskell-1-a-simple-solutionSudoku is a number placement puzzle. It consists of a 9x9 grid which is to be filled with digits from 1 to 9. Some of the cells of the grid come pre-filled and the player has to fill the rest.
Haskell is a purely functional programming language. It is a good choice to solve Sudoku given the problem’s combinatorial nature. The aim of this series of posts is to write a fast Sudoku solver in Haskell. We’ll focus on both implementing the solution and making it efficient, step-by-step, starting with a slow but simple solution in this post1.
Solving Sudoku is a constraint satisfaction problem. We are given a partially filled grid which we have to fill completely such that each of the following constraints are satisfied:
Each of the nine rows must have all the digits, from 1 to 9.
Each of the nine columns must have all the digits, from 1 to 9.
Each of the nine 3x3 sub-grids must have all the digits, from 1 to 9.
Each cell in the grid is member of one row, one column and one sub-grid (called block in general). Digits in the pre-filled cells impose constraints on the rows, columns, and sub-grids they are part of. For example, if a cell contains 1 then no other cell in that cell’s row, column or sub-grid can contain 1. Given these constraints, we can devise a simple algorithm to solve Sudoku:
Each cell contains either a single digit or has a set of possible digits. For example, a grid showing the possibilities of all non-filled cells for the sample puzzle above:
If a cell contains a digit, remove that digit from the list of the possible digits from all its neighboring cells. Neighboring cells are the other cells in the given cell’s row, column and sub-grid. For example, the grid after removing the fixed value 4 of the row-2-column-1 cell from its neighboring cells:
Repeat the previous step for all the cells that are have been solved (or fixed), either pre-filled or filled in the previous iteration of the solution. For example, the grid after removing all fixed values from all non-fixed cells:
Continue till the grid settles, that is, there are no more changes in the possibilities of any cells. For example, the settled grid for the current iteration:
Once the grid settles, choose one of the non-fixed cells following some strategy. Select one of the digits from all the possibilities of the cell, and fix (assume) the cell to have that digit. Go back to step 1 and repeat.
The elimination of possibilities may result in inconsistencies. For example, you may end up with a cell with no possibilities. In such a case, discard that branch of solution, and backtrack to last point where you fixed a cell. Choose a different possibility to fix and repeat.
If at any point the grid is completely filled, you’ve found the solution!
If you exhaust all branches of the solution then the puzzle is unsolvable. This can happen if it starts with cells pre-filled wrongly.
This algorithm is actually a Depth-First Search on the state space of the grid configurations. It guarantees to either find a solution or prove a puzzle to be unsolvable.
Setting up
We start with writing types to represent the cells and the grid:
A cell is either fixed with a particular digit or has a set of digits as possibilities. So it is natural to represent it as a sum type with Fixed and Possible constructors. A row is a list of cells and a grid is a list of rows.
We’ll take the input puzzle as a string of 81 characters representing the cells, left-to-right and top-to-bottom. An example is:
Here, . represents an non-filled cell. Let’s write a function to read this input and parse it to our Grid data structure:
readGrid ::String->MaybeGridreadGrid s|length s ==81=traverse (traverse readCell) . Data.List.Split.chunksOf 9$ s|otherwise=Nothingwhere readCell '.'=Just$Possible [1..9] readCell c| Data.Char.isDigit c && c >'0'=Just.Fixed. Data.Char.digitToInt $ c|otherwise=Nothing
readGrid return a Just grid if the input is correct, else it returns a Nothing. It parses a . to a Possible cell with all digits as possibilities, and a digit char to a Fixed cell with that digit. Let’s try it out in the REPL:
The output is more readable now. We see that, at the start, all the non-filled cells have all the digits as possible values. We’ll use these functions for debugging as we go forward. We can now start solving the puzzle.
Pruning the Cells
We can remove the digits of fixed cells from their neighboring cells, one cell as a time. But, it is faster to find all the fixed digits in a row of cells and remove them from the possibilities of all the non-fixed cells of the row, at once. Then we can repeat this pruning step for all the rows of the grid (and columns and sub-grids too! We’ll see how).
pruneCells :: [Cell] ->Maybe [Cell]pruneCells cells =traverse pruneCell cellswhere fixeds = [x |Fixed x <- cells] pruneCell (Possible xs) =case xs Data.List.\\ fixeds of [] ->Nothing [y] ->Just$Fixed y ys ->Just$Possible ys pruneCell x =Just x
pruneCells prunes a list of cells as described before. We start with finding the fixed digits in the list of cells. Then we go over each non-fixed cells, removing the fixed digits we found, from their possible values. Two special cases arise:
If pruning results in a cell with no possible digits, it is a sign that this branch of search has no solution and hence, we return a Nothing in that case.
If only one possible digit remains after pruning, then we turn that cell into a fixed cell with that digit.
We use the traverse function for pruning the cells so that a Nothing resulting from pruning one cell propagates to the entire list.
Let’s take it for a spin in the REPL:
*Main>Just grid = readGrid "6......1.4.........2...........5.4.7..8...3....1.9....3..4..2...5.1........8.6..."*Main>putStr$ showGridWithPossibilities $ [head grid] -- first row of the grid6 [123456789] [123456789] [123456789] [123456789] [123456789] [123456789] 1 [123456789]*Main>putStr$ showGridWithPossibilities [fromJust $ pruneCells $head grid] -- same row after pruning6 [ 2345789] [ 2345789] [ 2345789] [ 2345789] [ 2345789] [ 2345789] 1 [ 2345789]
It works! 6 and 1 are removed from the possibilities of the other cells. Now we are ready for …
Pruning the Grid
Pruning a grid requires us to prune each row, each column and each sub-grid. Let’s try to solve it in the REPL first:
By traverse-ing the grid with pruneCells, we are able to prune each row, one-by-one. Since pruning a row doesn’t affect another row, we don’t have to pass the resulting rows between each pruning step. That is to say, traverse is enough for us, we don’t need foldl here.
How do we do the same thing for columns now? Since our representation for the grid is rows-first, we first need to convert it to a columns-first representation. Luckily, that’s what Data.List.transpose function does:
First, we transpose the grid to convert the columns into rows. Then, we prune the rows by traverse-ing pruneCells over them. And finally, we turn the rows back into columns by transpose-ing the grid back again. The last transpose needs to be fmap-ped because traverse pruneCells returns a Maybe.
Pruning sub-grids is a bit trickier. Following the same idea as pruning columns, we need two functions to transform the sub-grids into rows and back. Let’s write the first one:
subGridsToRows ::Grid->GridsubGridsToRows =concatMap (\rows ->let [r1, r2, r3] =map (Data.List.Split.chunksOf 3) rowsinzipWith3 (\a b c -> a ++ b ++ c) r1 r2 r3). Data.List.Split.chunksOf 3
You can go over the code and the output and make yourself sure that it works. Also, it turns out that we don’t need to write the back-transform function. subGridsToRows is its own back-transform:
It works well. Now we can string together these three steps to prune the entire grid. We also have to make sure that result of pruning each step is fed into the next step. This is so that the fixed cells created into one step cause more pruning in the further steps. We use monadic bind (>>=) for that. Here’s the final code:
We can clearly see the massive pruning of possibilities all around the grid. We also see a 7 pop up in the row-7-column-5 cell. This means that we can prune the grid further, until it settles. If you are familiar with Haskell, you may recognize this as trying to find a fixed point for the pruneGrid' function, except in a monadic context. It is simple to implement:
pruneGrid ::Grid->MaybeGridpruneGrid = fixM pruneGrid'where fixM f x = f x >>= \x' ->if x' == x thenreturn x else fixM f x'
The crux of this code is the fixM function. It takes a monadic function f and an initial value, and recursively calls itself till the return value settles. Let’s do another round in the REPL:
We see that 7 in the row-7-column-5 cell is eliminated from all its neighboring cells. We can’t prune the grid anymore. Now it is time to make the choice.
Making the Choice
One the grid is settled, we need to choose a non-fixed cell and make it fixed by assuming one of its possible values. This gives us two grids, next in the state-space of the solution search:
one which has this chosen cell fixed to this chosen digit, and,
the other in which the chosen cell has all the other possibilities except the one we chose to fix.
We call this function, nextGrids:
nextGrids ::Grid-> (Grid, Grid)nextGrids grid =let (i, first@(Fixed _), rest) = fixCell. Data.List.minimumBy (compare`Data.Function.on` (possibilityCount .snd)).filter (isPossible .snd).zip [0..].concat$ gridin (replace2D i first grid, replace2D i rest grid)where isPossible (Possible _) =True isPossible _ =False possibilityCount (Possible xs) =length xs possibilityCount (Fixed _) =1 fixCell (i, Possible [x, y]) = (i, Fixed x, Fixed y) fixCell (i, Possible (x:xs)) = (i, Fixed x, Possible xs) fixCell _ =error"Impossible case" replace2D ::Int-> a -> [[a]] -> [[a]] replace2D i v =let (x, y) = (i `quot`9, i `mod`9) in replace x (replace y (const v)) replace p f xs = [if i == p then f x else x | (x, i) <-zip xs [0..]]
We choose the non-fixed cell with least count of possibilities as the pivot. This strategy make sense intuitively, as with a cell with fewest possibilities, we have the most chance of being right when assuming one. Fixing a non-fixed cell leads to one of the two cases:
the cell has only two possible values, resulting in two fixed cells, or,
the cell has more than two possible values, resulting in one fixed and one non-fixed cell.
Then all we are left with is replacing the non-fixed cell with its fixed and fixed/non-fixed choices, which we do with some math and some list traversal. A quick check on the REPL:
We have implemented parts of our algorithm till now. Now we’ll put everything together to solve the puzzle. First, we need to know if we are done or have messed up:
isGridFilled returns whether a grid is filled completely by checking it for any Possible cells. isGridInvalid checks if a grid is invalid because it either has duplicate fixed cells in any block or has any non-fixed cell with no possibilities.
We prune the grid as before and pipe it to the helper function solve'. solve' bails with a Nothing if the grid is invalid, or returns the solved grid if it is filled completely. Otherwise, it finds the next two grids in the search tree and solves them recursively with backtracking by calling the solve function. Backtracking here is implemented by the using the Alternative (<|>) implementation of the Maybe type2. It takes the second branch in the computation if the first branch returns a Nothing.
Whew! That took us long. Let’s put it to the final test now:
If you want to play with different puzzles, the file here lists some of the toughest ones. Let’s run3 some of them through our program to see how fast it is:
$ head -n100 sudoku17.txt | time stack exec sudoku
... output omitted ...
116.70 real 198.09 user 94.46 sys
It took about 117 seconds to solve a hundred puzzles, so, about 1.2 seconds per puzzle. This is pretty slow but we’ll get around to making it faster in the subsequent posts.
Conclusion
In this rather verbose article, we learned how to write a simple Sudoku solver in Haskell step-by-step. In the later parts of this series, we’ll delve into profiling the solution and figuring out better algorithms and data structures to solve Sudoku more efficiently. The code till now is available here. Discuss this post on r/haskell or leave a comment.
]]><![CDATA[Finances in an Employee-Owned Technology Co-operative]]>2018-05-23T00:00:00+00:00http://blog.nilenso.com/blog/2018/05/23/finances-in-an-employee-owned-technology-co-operaIf you are not already familiar with nilenso, I apologize. This article may not make any sense to you. Requested as an opinion piece in reply to an internal email on salaries, it hinges on a lot of context.
blog archive — the rest of the articles we’ve written
The email which spawned this discussion was from a new employee, suggesting that we raise salaries. We discuss such organizational and infrastructural changes on occasion (not often) and an open conversation is welcome.
However, as I’m leaving nilenso in July, it felt worthwhile to capture what would otherwise be a one-time, long-winded email to nilenso’s existing staff and transform that into an article which could capture one founding member’s opinion of what nilenso is, for all future staff — and other fans of Employee-owned Co-operatives—who would care to read it.
On Salaries
The original email had a fairly simple 3-part structure.
First: How much can we pay? …without compromising on organizational goals like maintaining a rainy-day cash buffer and financing experimental new ventures?
Second, a declaration of our rates & salaries. Highlighted is the delta between the two. Our rates vary a lot from project to project, but for the sake of example, imagine our rates average to $100/hour. (100 is a nice round number.) At $100/hour, our rates were high for Indian software consultancies, but not astronomical. A napkin calculation roughs $100/hour to over $100,000/year in revenue. Historically, very senior people at nilenso made about half this revenue figure as salary.
[F]or people with more experience and established reputation, there is an incentive to break away and start their own business so that they can pocket the difference.
(All quotes are from the aforementioned email.)
Third and last, a spectrum of starting salaries. These were listed for college grads of reputable Indian universities, such as NIT and IIT. Paymasters near the top included Uber and Goldman Sachs. Near the bottom were Samsung and American Express.
Some of the people I know from college are very good programmers and I’ll have a very hard [time] convincing them to join Nilenso [sic], because the difference between our salaries and the industry “standard” is too large.
….
[M]ost of our clients can pay pretty high salaries. From their perspective it isn’t an unreasonable strategy to hire a bunch of folks from nilenso instead of negotiating our high rates
It is possible this argument doesn’t seem irrational in isolation, so let’s break it down part by part. From hereon out, please automatically prefix any declaration I make with “as of this writing.”
Part 3: A unicorn pissing contest
Let’s start from the end, since—tellingly—the actionable question was actually posed first.
There are a number of reasons our clients have not frequently hired our staff away. First, and most strictly, some contracts we sign have a two-way no-hire clause. In these cases, our clients cannot hire our employees and we cannot hire theirs. However, just because the contract does not forbid poaching does not make it a good idea. Our preferred engagement model is a long-term, cooperative and collaborative relationship; if either side starts yanking the other entity’s employees, that’s a great way to either poison the engagement.
In addition to all of this, however, there is sustainability at stake. As global consultancies go, nilenso is very small and very good. The author of the email is our 20th co-op member. Unless a client is very comfortable burning bridges, hiring two of our staff today trims our numbers by a non-trivial 10%. We don’t work with cannibal business owners.
That isn’t to say no one has ever left nilenso this way. If it happens, we simply hope that person takes their decision very seriously. Some of our alumni left to join past clients — and we wished them well.
People do not work at nilenso to get rich.
People work here because they believe in something. As we’ll see, “something” isn’t defined by some manifesto or mission statement. The “something” isn’t likely to be found elsewhere and it’s even less likely to be the same for two different people at nilenso. “Something” probably isn’t a single thing within the mind of a single person. “Something” is fractured and ever-changing. Each fractured shard is at any given time either a hallucination manifesting in action or a miscalculation fading to black.
As complex as The Somethings are, there has thus far been a few consistent threads. One? Technical excellence. A potential client from Vietnam recently asked “what is the ratio of fresh grads you hire to senior developers?” Though it may not appear so on the surface, the idea that “I’ll have a very hard [time] convincing [people I know from college] to join” stems from the very same misconception.
nilenso is not a leveraged consultancy.
The misconception is that nilenso desires to behave as other consultancies by “leveraging”** their weakest employees (read: fresh grads) and charging the highest possible rate by inflating them with as few “senior”** developers as possible. The misconception is not unfounded. Most consultancies operate this way. We do not.
** industry terminology, not mine
Convincing college grads to apply to nilenso is not a problem we’d like to solve. We have college grads begging us for internships and offering to work for free.
We do not want to hire college grads.
When our clients hire nilenso, we don’t want them satisfied. We want them elated. With one or two exceptions, our most junior developers always have multiple years of experience. They joined us because they couldn’t find their Something anywhere else in the industry. Not only has a college grad not, by definition, owned her own software in production — she hasn’t had an opportunity to go look for Something yet. Go searching first—and learn to build and deploy software while you’re at it. Maybe she’ll find her Something. If she doesn’t, she can join a company like ours.
Some of us have worked for companies like these and we have done everything in our power to prevent nilenso from becoming such a company. We don’t need revenue in the billions to behave this way but racing to compete salaries with such companies does us zero favours in that arena.
There is perhaps no better way for a college kid to learn the value of a company like nilenso than to experience a cesspool like Uber firsthand for a couple years. Not that I recommend the grads start their search there, mind you.
Part 2: Where is all this magical money coming from?
In “Part 3”, when I say that nilenso is “very small and very good” I mean that from the bottom of my heart. We are very good. We don’t fantasize about our clients paying us $100/hour — our current clients pay us this because we are worth it. Our first month with every new client is always evaluatory (we even did a 3-month evaluation period once). This is an opportunity for our clients to fire us if they find us too expensive and for us to fire them if we find the relationship isn’t productive.
Why are our developers worth well over $10,000 USD per month?
There is a watermark here. One can calculate the watermark in a number of ways. The first and most obvious is: How many people at nilenso have ever been paid $120,000/year or higher in any country? Two. So that probably puts the watermark too high. How many people at nilenso could be paid $120,000/year (roughly 77 lakh rupees) today — specifically in Bangalore? Three.
These numbers are clearly too low. The entire value of our company does not hinge on two or three people. But these are the only objective numbers we have on this axis. If we wanted to reach for a subjective number, we could say the watermark exists beneath anyone to whom our rates can be actively attributed. I would say these people number seven.
Seven of twenty active knowledge workers does not mean we “leverage” (ugh, that word) the other thirteen. Other folks are very close or arguably cross this watermark. But every team has a natural pecking order (a hierarchy drawn in a straight line, whether you draw it with a pen or with your mind) and wherever we assume this watermark to be, our value to our customers is more than the sum of the parts.
The flaw in the “wow, we make so much money!” argument is that no matter where you place this watermark, you must actively acknowledge from where this value is generated: above the watermark. If there is an argument to be made for altering the salary curve to reflect this, that alteration always implies an inflection point at the watermark. People above the watermark should be paid more. People below the watermark should be paid less. Your financial goals as an employee of such a company are dictated by your ability to cross the watermark and stay above it.
That doesn’t sound like a place I’d like to work.
I’m guessing the author of the original email feels the same way. Being our most junior staff member means starting at the very bottom of this curve and a search for the source of a consultancy’s value is always upward-facing. That’s a big hill to climb and it’s a lot more likely that crossing the watermark will involve nilenso growing from 20 to 40 rather than the most junior employee leapfrogging over 10 other people. We grow slowly on purpose — and it’s not to keep junior people at the bottom of the pay scale.
We would rather grow inside. We want our most junior staff to become more senior not by stacking themselves on top of new junior people but by perfecting their execution.
[F]or people with more experience and established reputation, there is an incentive to break away and start their own business so that they can pocket the difference.
No one at nilenso has ever done this. Why not?
Part 1: Where does all this money go?
Now we get to the juicy bits. The interesting question is not “how much can we pay?” at all. If someone wants to double her salary she can very easily do so today and nilenso is entirely unequipped to deal with that except to wish her the best with her new job.
People do not work at nilenso to get rich.
People work at nilenso to find… something. Something. What is that Something? To answer this, we must ask: What is nilenso? This is the interesting question.
Nilenso Software LLP is, today, a co-op; nilenso is self-hosted. It is written in a homoiconic language. It is self-referential. It is self-describing. The specification is the paper the specification is written on. And while none of these qualities are the Something we were all after, they are the qualities which equip us to do anything we want with the company. We are uninhibited in finding our Somethings if we never need to beg for VC money, never need to give up control, and never need to grow before we’re ready.
“Anything we want” can include bumping our salaries by 10% or 50%. It can include handing out bonuses. It can include democratically deciding we want to execute across-the-board pay cuts. But these are all pretty boring axes to manipulate the business. You don’t have to work at a co-op (and therefore run it) for very long to realize the the classic definitions of success are mind-numbingly boring… albeit always tempting.
Anything we want? Here is a far more interesting list:
helping parents raise children in the modern world
protect privacy as a fundamental right
fuel our office with solar panels
make the activity of building free software a work of pride, again
liberate the data sciences with truly open data
globally redefine what constitutes a “normal workplace”
what do you want to do? does it take money to do it? (hint: yes)
Every rupee we keep inside nilenso, invest as nilenso, or spend as nilenso pushes us further toward a collective activity, a collective vision. Every rupee we divide and distribute, 5 paise per co-op member, is a step away from a collective vision. The farthest we can go in this direction is to distribute everything: nilenso saves nothing, invests nothing, and builds nothing. Well before that stage, nilenso becomes an Umbrella Consultancy and we are nilenso in name only… another army of contractors with a brand attached and a few rupees saved every month to pay the water bill.
It is entirely valid for the collective vision of nilenso to be “we don’t want to have a collective vision” but once that is decided, there is no going back. If you want to become a software product company (as we attempted with Relay and previously attempted with Kulu), an electric rickshaw taxi service (a business model we have seriously considered), or a cafe (a business model we have jokingly considered)… you can’t. You get to go back to Square One, where we were when we incorporated nilenso in 2013. But you get to go back with no money and no way to compete on salaries but to rebuild a vision from scratch.
Good luck. It wasn’t easy the first time.
Epilogue
There is no easy way to think about the future regarding corporate or personal finances and arrive at novel conclusions. Follow Steve Jobs’ advice, drop enough acid, and you may. But you are still unlikely to execute based on these conclusions when you are sober on Monday. Such contemplations demand an entire suite of thought exercises. This is my favourite:
Flip the Five Whys exercise around and you have the And Then What? exercise.
Once you are rich, then what? Once you have solved the original problem, then what? Once you have solved an entire category of problems, then what? Once you have taught others to do it, then what?
And then what?
And then what?
]]><![CDATA[Designing for Open Source Software]]>2018-04-09T00:00:00+00:00http://blog.nilenso.com/blog/2018/04/09/designing-for-open-source-softwareMattermost → Relay
When you hear the words “open source” attached to a product, what image comes to mind? Do you imagine an office full of designers obsessing over every little pixel? Or do you imagine an army of alpha-nerds piecing together a slap-dash knockoff of some proprietary software?
We all believe open source software is badly designed because, historically, it was. (#NotAllOpenSourceSoftware)
Thirty years ago, in 1988, the very concept of a license or design language for software was far beyond the average person. A decade later, everything was still awful. Software barely worked. Your PC definitely had a virus on it. HTML had a <blink> tag. Installing Linux required weeks of patience and belief in oneself — the kind of conviction I would need to train for a marathon. If there is one canonical failure we can promote as the poster child of this dark era, it is OpenOffice. Or StarOffice or LibreOffice or Apache OpenOffice or OOo or AOO or whatever name you might know it by. When the very name of the product is this broken it’s unlikely to succeed as a brand.
Fast forward ten more years. As of 2008, Firefox was eating Microsoft’s lunch. Firefox was open source, fast, and standards-compliant. It was easy to like Firefox. But we didn’t like Firefox. We loved Firefox. Firefox had a brand before it was Firefox. A brand isn’t a snappy name and a cute logo. Your product is your brand and your product is dictated by its design.
In 2018, user expectations demand that design asymptotically approach perfection: your product better be open, compatible, clean, fast, and powerful. When nilenso first made the move from Slack to Mattermost, we kept all of this in mind. From our very first deployment of Mattermost it felt whole. We chose Mattermost because it was so very close to the design we wanted, we knew we could help bring it the rest of the way.
The beginning
The design problems that currently exist with Mattermost aren’t just visual but interaction and experience related. One of the first issues we took up was adding infinite scroll to the channel history. We couldn’t fathom why users should manually click to load every page of history. So we fixed it!
In the not-too-distant future we will add all the little nuanced details which transform Relay into software you absolutely love. At the moment, however, our aim is to solve the obvious problems our users have with the Mattermost/Relay experience. Like infinite scroll, these are the problems that left our early users shouting at us “ugh… how have you not fixed this yet?!”
Such problems stem from the pains caused by inconsistencies and visual discrepancies which hamper usability. It is surprising to many how quickly these seemingly small issues amount to death by a thousand papercuts. It is equally surprising how quickly software becomes a joy to use once you get the basics right.
We’ll start with the basics — icons and fonts — and then move on to the specifics of how we redesigned Mattermost as Relay, piece by piece.
Icons
When we moved from Slack to Mattermost the difference in icons used was stark. All icons used in Mattermost were inconsistent with respect to weights. They were standing out of the interface rather than blending in.
After further digging, we realised that Mattermost uses the free version of Font Awesome. Don’t get me wrong, I love the guys at Font Awesome; I even backed their kickstarter. But not all icons being available in the free weights (regular & solid) is quite a bummer.
We had three rules for selecting an icon set:
Icons must be open source
Icons need to be extensive
Icons need to be available in different styles (line and solid)
Allow me to interrupt with an aside. Technically, it is possible for us to build commercial artefacts into the Relay client by keeping them out of the source tree, even though Relay is AGPL3-licensed (as a derivative of the mattermost-webapp). Why, then, do we feel it is essential that the icons be open source? Relay lives at the intersection of the principles of Free Software and the license which governs it. Relay stands on the shoulders of giants — not only the Mattermost source code but Linux, GoLang, React, and hundreds of other projects. Here, between the spirit and the letter of Open Philosophies, exists a great deal of nuance. Cutting through this nuance is a root concept, however: “share alike.” If we take something from the free/open software community, what we return to that community should afford the next recipient the same freedoms we had. If we tweak Relay’s design until it is absolutely perfect but that involves changes which Mattermost cannot absorb upstream, we have failed them and every other project we have built ourselves upon. Thus, our icons must have an open license. — Steven Deobald
Thanks Steve. Keeping the above mentioned points in mind, there were three icon sets that made the final round of discussion:
We chose the Clarity icon set because of styles, consistency, and the icons being part of a design language system. Clarity is an open source design system created and maintained by the good folks at VMware. Since VMware has a dedicated team pushing continuous updates there is little fear the icon set will be abandoned or go stale.
Font
Our font selection followed the same rules:
Fonts must be open source
Fonts should be available in multiple weights
…along with these additions:
Fonts with large x-height for easy readability
Fonts with thick Regular weight so fonts will be crisp
We stress so much on font weights because Relay is, first and foremost, a messaging tool. In Relay, you spend most of your time reading and we want this experience to be as enjoyable as possible. Relay also has complete Markdown support and weights help establish hierarchy both within the app and within the messages themselves.
We had a few contenders which satisfied these requirements. PT Sans, Lato, and Noto Sans all have an enjoyable reading experience but after a lot of trial and error we chose Fira Sans.
Fira Sans is an incredible font. It has a healthy variety of weights and the compressed nature of the font holds the messaging interface together while keeping it crisp.
Did you know that Fira Sans was built on top of Erik Spiekermann’s commercial font FF Meta? And that Spiekermann was commissioned by the Mozilla Foundation! Read the whole story here
How Mattermost became Relay
Implementing the design basics improved the existing experience. But to make those changes truly delightful we need to fine-tune every aspect of the app. We have started with three major sections:
Left sidebar
Channel header
Main messaging interface
Present Mattermost interface
1. Left sidebar
The sidebar’s Team section allows users to switch between teams within organisations that they’re a part of. The current Mattermost implementation truncates the team name and adds a byline. The problem with this is that it does not add any value since hovering over the team opens a tooltip with the team name anyway. We removed the byline and the truncated text.
The sidebar’s Channel section felt mashed together. There is a clear hierarchy intended, which includes channel headers such as “Favorite Channels” and a distinction between active and inactive channels. We brought this hierarchy to the surface. Active channels have a heavy weight and inactive channels fade away with a lower opacity, despite the increased crispness of Fira Sans.
Grouped channels now have tighter spacing and groups themselves have larger spacing, allowing group titles to have a smaller font. All together, this makes the hierarchy obvious even at a glance.
2. Channel header
In the channel header we cleaned up the icons. Here are the issues we encountered with the icons:
Most icons weren’t of the same weight
Some icons were of a different size
Some icons had some positioning overrides to align them
The old icons for the channel header stood out, drawing attention away from the main chat area. We wanted them instead to blend into the design — unobtrusive but still obvious. To do this we removed the borders and switched the icon set to Clarity.
In addition to icons, we fixed the CSS for the header and right sidebar, getting rid of all funny margins and relative positioning. We also added consistent heights, paddings, and sizes for each of the icons. These fixes don’t just add polish to the UI; once merged, they will also ensure it is easier for anyone in the community, including us, to customise Mattermost.
3. Messaging interface
The messaging interface is where users spend the most time. The messaging interface is also where Mattermost has most of its design inconsistencies, which are most glaring in the basics: alignment, spacing between posts, font size, and other elements on the interface such as the reply box.
After we moved to Fira Sans we bumped up the font size, made sure the headings and names are bolded to establish hierarchy, and fixed alignment and spacing issues to deliver a crisper and more enjoyable reading experience.
Themes
Accessibility matters. We have light-sensitive coworkers and we’re sure you do, too. That’s why Relay comes with light and dark themes out of the box.
There are many Relay/Mattermost-compatible themes available already but we will pour all our energy into these two. They already make Relay beautiful and with every kaizen they will only get better.
Of course, we don’t restrict you to these two themes. Relay also comes with community themes and Relay’s entire colour scheme is fully customisable… not just the sidebar (*cough* Slack *cough*). We are working to make Relay 100% customisable through CSS so users have complete control over every aspect of the UI, if they want.
Putting it all together
By following a consistent design language for icons, font, and themes we ensure all our “pieces” are whole unto themselves. Putting them back together, the application itself becomes whole.
Sign up, try the redesign, and tell us what you think!
Along with visual design changes, Relay also aims to significantly improve its user experience. Our public Trello board contains our plan for Relay’s future.
Future
“Design” is the 8th most popular tag on Medium. “Open Source” is ranked 290. Source code licenses will never be sexy for the same reason your city’s water utility company will never be. The water supply is inherently a part of your city’s design. Similarly, your freedom as a user is designed into software you buy. Your ownership of a product is but one more limb in the tree of design.
Open source software needs good design because good design respects you, the user.
Designing for Open Source Software was originally published in The Relay on Medium, where people are continuing the conversation by highlighting and responding to this story.
]]><![CDATA[Writing a Simple REST Web Service in PureScript - Part 2]]>2017-10-01T00:00:00+00:00http://blog.nilenso.com/blog/2017/10/01/writing-a-simple-rest-web-service-in-purescript-pTo recap, in the first part of this two-part tutorial, we built a simple JSON REST web service in PureScript to create, update, get, list and delete users, backed by a Postgres database. In this part we’ll work on the rest of the features. The requirements are:
validation of API requests.
reading the server and database configs from environment variables.
logging HTTP requests and debugging info.
But first,
Bugs!
What happens if we hit a URL on our server which does not exist? Let’s fire up the server and test it:
We get back a default HTML response with a 404 status from Express. Since we are writing a JSON API, we should return a JSON response in this case too. We add the following code in the src/SimpleService/Server.purs file to add a catch-all route and send a 404 status with a JSON error message:
-- previous codeimportData.Either (fromRight)importData.String.Regex (Regex, regex) asReimportData.String.Regex.Flags (noFlags) asReimportNode.Express.App (App, all, delete, get, http, listenHttp, post, useExternal)importNode.Express.Response (sendJson, setStatus)importPartial.Unsafe (unsafePartial)-- previous codeallRoutePattern ::Re.RegexallRoutePattern = unsafePartial $ fromRight $ Re.regex "/.*" Re.noFlagsapp ::forall eff.PG.Pool->App (postgreSQL ::PG.POSTGRESQL| eff)app pool =do useExternal jsonBodyParser get "/v1/user/:id"$ getUser pool delete "/v1/user/:id"$ deleteUser pool post "/v1/users"$ createUser pool patch "/v1/user/:id"$ updateUser pool get "/v1/users"$ listUsers poolall allRoutePattern do setStatus 404 sendJson {error:"Route not found"}where patch = http (CustomMethod"patch")
allRoutePattern matches all routes because it uses a "/.*"regular expression. We place it as the last route to match all the otherwise unrouted requests. Let’s see what is the result:
$ http GET https://localhost:4000/v1/random
HTTP/1.1 404 Not Found
Connection: keep-alive
Content-Length: 27
Content-Type: application/json; charset=utf-8
Date: Sat, 30 Sep 2017 08:46:46 GMT
ETag: W/"1b-772e0u4nrE48ogbR0KmKfSvrHUE"
X-Powered-By: Express
{
"error": "Route not found"
}
Now we get a nicely formatted JSON response.
Another scenario is when our application throws some uncaught error. To simulate this, we shut down our postgres database and hit the server for listing users:
We get another default HTML response from Express with a 500 status. Again, in this case we’d like to return a JSON response. We add the following code to the src/SimpleService/Server.purs file:
It works! Bugs are fixed now. We proceed to add next features.
Validation
Let’s recall the code to update a user from the src/SimpleService/Handler.purs file:
updateUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)updateUser pool = getRouteParam "id">>=case _ ofNothing-> respond 422 { error:"User ID is required" }Just sUserId ->case fromString sUserId ofNothing-> respond 422 { error:"User ID must be positive: "<> sUserId }Just userId -> getBody >>=case _ ofLeft errs -> respond 422 { error: intercalate ", "$map renderForeignError errs}Right (UserPatch userPatch) ->case unNullOrUndefined userPatch.name ofNothing-> respondNoContent 204Just userName ->if userName ==""then respond 422 { error:"User name must not be empty" }elsedo savedUser <- liftAff $ PG.withConnection pool \conn -> PG.withTransaction conn do P.findUser conn userId >>=case _ ofNothing->pureNothingJust (User user) ->dolet user' =User (user { name = userName }) P.updateUser conn user'pure$Just user'case savedUser ofNothing-> respond 404 { error:"User not found with id: "<> sUserId }Just user -> respond 200 (encode user)
As we can see, the actual request handling logic is obfuscated by the request validation logic for the user id and the user name patch parameters. We also notice that we are using three constructs for validation here: Maybe, Either and if-then-else. However, we can use just Either to subsume all these cases as it can “carry” a failure as well as a success case. Either also comes with a nice monad transformer ExceptT which provides the do syntax for failure propagation. So we choose ExceptT as the base construct for our validation framework and write functions to upgrade Maybe and if-then-else to it. We add the following code to the src/SimpleService/Validation.purs file:
moduleSimpleService.Validation (moduleMoreExports, moduleSimpleService.Validation) whereimportPreludeimportControl.Monad.Except (ExceptT, except, runExceptT)importData.Either (Either(..))importData.Maybe (Maybe(..))importNode.Express.Handler (HandlerM, Handler)importNode.Express.Response (sendJson, setStatus)importNode.Express.Types (EXPRESS)importControl.Monad.Except (except) asMoreExportstypeValidation eff a =ExceptTString (HandlerM (express ::EXPRESS| eff)) aexceptMaybe ::forall e m a.Applicative m => e ->Maybe a ->ExceptT e m aexceptMaybe e a = except $case a ofJust x ->Right xNothing->Left eexceptCond ::forall e m a.Applicative m => e -> (a ->Boolean) -> a ->ExceptT e m aexceptCond e cond a = except $if cond a thenRight a elseLeft ewithValidation ::forall eff a.Validation eff a -> (a ->Handler eff) ->Handler effwithValidation action handler = runExceptT action >>=case _ ofLeft err ->do setStatus 422 sendJson {error: err}Right x -> handler x
We re-export except from the Control.Monad.Except module. We also add a withValidation function which runs an ExceptT based validation and either returns an error response with a 422 status in case of a failed validation or runs the given action with the valid value in case of a successful validation.
Using these functions, we now write updateUser in the src/SimpleService/Handler.purs file as:
-- previous codeimportControl.Monad.Trans.Class (lift)importData.Bifunctor (lmap)importData.Foreign (ForeignError, renderForeignError)importData.List.NonEmpty (toList)importData.List.Types (NonEmptyList)importData.Tuple (Tuple(..))importSimpleService.ValidationasV-- previous coderenderForeignErrors ::forall a.Either (NonEmptyListForeignError) a ->EitherString arenderForeignErrors = lmap (toList >>>map renderForeignError >>> intercalate ", ")updateUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)updateUser pool = V.withValidation (Tuple<$> getUserId <*> getUserPatch) \(Tuple userId (UserPatch userPatch)) ->case unNullOrUndefined userPatch.name ofNothing-> respondNoContent 204Just uName -> V.withValidation (getUserName uName) \userName ->do savedUser <- liftAff $ PG.withConnection pool \conn -> PG.withTransaction conn do P.findUser conn userId >>=case _ ofNothing->pureNothingJust (User user) ->dolet user' =User (user { name = userName }) P.updateUser conn user'pure$Just user'case savedUser ofNothing-> respond 404 { error:"User not found with id: "<>show userId }Just user -> respond 200 (encode user)where getUserId = lift (getRouteParam "id")>>= V.exceptMaybe "User ID is required">>= fromString >>> V.exceptMaybe "User ID must be positive" getUserPatch = lift getBody >>= V.except <<< renderForeignErrors getUserName = V.exceptCond "User name must not be empty" (_ =="")
The validation logic has been extracted out in separate functions now which are composed using Applicative. The validation steps are composed using the ExceptT monad. We are now free to express the core logic of the function clearly. We rewrite the src/SimpleService/Handler.purs file using the validations:
moduleSimpleService.HandlerwhereimportPreludeimportControl.Monad.Aff.Class (liftAff)importControl.Monad.Trans.Class (lift)importData.Bifunctor (lmap)importData.Either (Either)importData.Foldable (intercalate)importData.Foreign (ForeignError, renderForeignError)importData.Foreign.Class (encode)importData.Foreign.NullOrUndefined (unNullOrUndefined)importData.Int (fromString)importData.List.NonEmpty (toList)importData.List.Types (NonEmptyList)importData.Maybe (Maybe(..))importData.Tuple (Tuple(..))importDatabase.PostgreSQLasPGimportNode.Express.Handler (Handler)importNode.Express.Request (getBody, getRouteParam)importNode.Express.Response (end, sendJson, setStatus)importSimpleService.PersistenceasPimportSimpleService.ValidationasVimportSimpleService.TypesgetUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)getUser pool = V.withValidation getUserId \userId -> liftAff (PG.withConnection pool $flip P.findUser userId) >>=case _ ofNothing-> respond 404 { error:"User not found with id: "<>show userId }Just user -> respond 200 (encode user)deleteUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)deleteUser pool = V.withValidation getUserId \userId ->do found <- liftAff $ PG.withConnection pool \conn -> PG.withTransaction conn do P.findUser conn userId >>=case _ ofNothing->pure falseJust _ ->do P.deleteUser conn userIdpure trueif foundthen respondNoContent 204else respond 404 { error:"User not found with id: "<>show userId }createUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)createUser pool = V.withValidation getUser \user@(User _) ->do liftAff (PG.withConnection pool $flip P.insertUser user) respondNoContent 201where getUser = lift getBody>>= V.except <<< renderForeignErrors>>= V.exceptCond "User ID must be positive" (\(User user) -> user.id>0)>>= V.exceptCond "User name must not be empty" (\(User user) -> user.name /="")updateUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)updateUser pool = V.withValidation (Tuple<$> getUserId <*> getUserPatch) \(Tuple userId (UserPatch userPatch)) ->case unNullOrUndefined userPatch.name ofNothing-> respondNoContent 204Just uName -> V.withValidation (getUserName uName) \userName ->do savedUser <- liftAff $ PG.withConnection pool \conn -> PG.withTransaction conn do P.findUser conn userId >>=case _ ofNothing->pureNothingJust (User user) ->dolet user' =User (user { name = userName }) P.updateUser conn user'pure$Just user'case savedUser ofNothing-> respond 404 { error:"User not found with id: "<>show userId }Just user -> respond 200 (encode user)where getUserPatch = lift getBody >>= V.except <<< renderForeignErrors getUserName = V.exceptCond "User name must not be empty" (_ /="")listUsers ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)listUsers pool = liftAff (PG.withConnection pool P.listUsers) >>= encode >>> respond 200getUserId ::forall eff.V.Validation eff IntgetUserId = lift (getRouteParam "id")>>= V.exceptMaybe "User ID is required">>= fromString >>> V.exceptMaybe "User ID must be an integer">>= V.exceptCond "User ID must be positive" (_ >0)renderForeignErrors ::forall a.Either (NonEmptyListForeignError) a ->EitherString arenderForeignErrors = lmap (toList >>>map renderForeignError >>> intercalate ", ")respond ::forall eff a.Int-> a ->Handler effrespond status body =do setStatus status sendJson bodyrespondNoContent ::forall eff.Int->Handler effrespondNoContent status =do setStatus status end
The code is much cleaner now. Let’s try out a few test cases:
$ http GET https://localhost:4000/v1/user/asdf
HTTP/1.1 422 Unprocessable Entity
Connection: keep-alive
Content-Length: 38
Content-Type: application/json; charset=utf-8
Date: Sat, 30 Sep 2017 12:14:40 GMT
ETag: W/"26-//tvORl1gGDUMwgSaqbEpJhuadI"
X-Powered-By: Express
{
"error": "User ID must be an integer"
}
$ http GET https://localhost:4000/v1/user/-1
HTTP/1.1 422 Unprocessable Entity
Connection: keep-alive
Content-Length: 36
Content-Type: application/json; charset=utf-8
Date: Sat, 30 Sep 2017 12:14:45 GMT
ETag: W/"24-Pvt1L4eGilBmVtaOGHlSReJ413E"
X-Powered-By: Express
{
"error": "User ID must be positive"
}
It works as expected.
Configuration
Right now our application configuration resides in the main function:
main = runServer port databaseConfigwhere port =4000 databaseConfig = { user:"abhinav" , password:"" , host:"localhost" , port:5432 , database:"simple_service" , max:10 , idleTimeoutMillis:1000 }
We are going to extract it out of the code and read it from the environment variables using the purescript-config package. First, we install the required packages using bower.
We use the applicative DSL provided in Data.Config module to build a description of our configuration. This description contains the keys and types of the configuration, for consumption by various interpreters. Then we use the fromEnv interpreter to read the config from the environment variables derived from the name fields in the records in the description in the readServerConfig function. We also write a bash script to set those environment variables in the development environment in the setenv.sh file:
If readServerConfig fails, we print the missing keys to the console and exit the process. Else we run the server with the read config.
To test this, we stop the server we ran in the beginning, source the config, and run it again:
$ pulp --watch run* Building project in /Users/abhinav/ps-simple-rest-service* Build successful.Server listening on :4000^C$ source setenv.sh$ pulp --watch run* Building project in /Users/abhinav/ps-simple-rest-service* Build successful.Server listening on :4000
It works! We test the failure case by opening another terminal which does not have the environment variables set:
$ pulp run* Building project in /Users/abhinav/ps-simple-rest-service* Build successful.Unable to start. Missing Env keys: SS_DB_DATABASE, SS_DB_HOST, SS_DB_IDLE_CONN_TIMEOUT_MILLIS, SS_DB_PASSWORD, SS_DB_POOL_SIZE, SS_DB_PORT, SS_DB_USER, SS_PORT* ERROR: Subcommand terminated with exit code 1
Up next, we add logging to our application.
Logging
For logging, we use the purescript-logging package. We write a logger which logs to stdout; in the src/SimpleService/Logger.purs file:
moduleSimpleService.Logger ( debug , info , warn , error ) whereimportPreludeimportControl.LoggerasLimportControl.Monad.Eff.Class (class MonadEff, liftEff)importControl.Monad.Eff.ConsoleasCimportControl.Monad.Eff.Now (NOW, now)importData.DateTime.Instant (toDateTime)importData.Either (fromRight)importData.Formatter.DateTime (Formatter, format, parseFormatString)importData.Generic.Rep (class Generic)importData.Generic.Rep.Show (genericShow)importData.String (toUpper)importPartial.Unsafe (unsafePartial)dataLevel=Debug|Info|Warn|Errorderive instance eqLevel ::EqLevelderive instance ordLevel ::OrdLevelderive instance genericLevel ::GenericLevel _instance showLevel ::ShowLevelwhereshow=toUpper<<< genericShowtypeEntry= { level ::Level , message ::String }dtFormatter ::FormatterdtFormatter = unsafePartial $ fromRight $ parseFormatString "YYYY-MM-DD HH:mm:ss.SSS"logger ::forall m e. (MonadEff (console ::C.CONSOLE, now ::NOW| e) m) =>L.Logger m Entrylogger =L.Logger$ \{ level, message } -> liftEff do time <- toDateTime <$> now C.log $"["<> format dtFormatter time <>"] "<>show level <>" "<> messagelog ::forall m e.MonadEff (console ::C.CONSOLE , now ::NOW| e) m=>Entry-> m Unitlog entry@{level} = L.log (L.cfilter (\e -> e.level == level) logger) entrydebug ::forall m e.MonadEff (console ::C.CONSOLE , now ::NOW| e) m =>String-> m Unitdebug message =log { level:Debug, message }info ::forall m e.MonadEff (console ::C.CONSOLE , now ::NOW| e) m =>String-> m Unitinfo message =log { level:Info, message }warn ::forall m e.MonadEff (console ::C.CONSOLE , now ::NOW| e) m =>String-> m Unitwarn message =log { level:Warn, message }error ::forall m e.MonadEff (console ::C.CONSOLE , now ::NOW| e) m =>String-> m Uniterror message =log { level:Error, message }
purescript-logging lets us define our own logging levels and loggers. We define four log levels, and a log entry type with the log level and the message. Then we write the logger which will print the log entry to stdout along with the current time as a well formatted string. We define convenience functions for each log level.
Before we proceed, let’s install the required dependencies.
We also convert all our previous logging statements which used Console.log to use SimpleService.Logger and add logs in our handlers. We can see logging in effect by restarting the server and hitting it:
$ pulp --watch run* Building project in /Users/abhinav/ps-simple-rest-service* Build successful.[2017-09-30 16:02:41.634] INFO Server listening on :4000[2017-09-30 16:02:43.494] DEBUG HTTP: PATCH /v1/user/3[2017-09-30 16:02:43.517] DEBUG Updated user: 3[2017-09-30 16:03:46.615] DEBUG HTTP: DELETE /v1/user/3[2017-09-30 16:03:46.635] DEBUG Deleted user 3[2017-09-30 16:05:03.805] DEBUG HTTP: GET /v1/users
Conclusion
In this tutorial we learned how to create a simple JSON REST web service written in PureScript with persistence, validation, configuration and logging. The complete code for this tutorial can be found in github. Discuss this post in the comments.
]]><![CDATA[Writing a Simple REST Web Service in PureScript - Part 1]]>2017-09-29T00:00:00+00:00http://blog.nilenso.com/blog/2017/09/29/writing-a-simple-rest-web-service-in-purescript-pAt Nilenso, we’ve been working with a client who has chosen PureScript as their primary programming language. Since I couldn’t find any canonical documentation on writing a web service in PureScript, I thought I’d jot down the approach that we took.
The aim of this two-part tutorial is to create a simple JSON REST web service written in PureScript, to run on a node.js server. This assumes that you have basic proficiency with PureScript. We have the following requirements:
persisting users into a Postgres database.
API endpoints for creating, updating, getting, listing and deleting users.
validation of API requests.
reading the server and database configs from environment variables.
logging HTTP requests and debugging info.
In this part we’ll work on setting up the project and on the first two requirements. In the next part we’ll work on the rest of the requirements.
Setting Up
We start with installing PureScript and the required tools. This assumes that we have node and npm installed on our machine.
Pulp is a build tool for PureScript projects and bower is a package manager used to get PureScript libraries. We’ll have to add ~/.local/bin in our $PATH (if it is not already added) to access the binaries installed.
Let’s create a directory for our project and make Pulp initialize it:
Pulp creates the basic project structure for us. src directory will contain the source while the test directory will contain the tests. bower.json contains the PureScript libraries as dependencies which are downloaded and installed in the bower_components directory.
Types First
First, we create the types needed in src/SimpleService/Types.purs:
We are using the generic support for PureScript types from the purescript-generics-rep and purescript-foreign-generic libraries to encode and decode the User type to JSON. We install the library by running the following command:
$ bower install purescript-foreign-generic --save
Now we can load up the module in the PureScript REPL and try out the JSON conversion features:
We use encodeJSON and decodeJSON functions from the Data.Foreign.Generic module to encode and decode the User instance to JSON. The return type of decodeJSON is a bit complicated as it needs to return the parsing errors too. In this case, the decoding returns no errors and we get back a Right with the correctly parsed User instance.
Persisting It
Next, we add the support for saving a User instance to a Postgres database. First, we install the required libraries using bower and npm: pg for Javascript bindings to call Postgres, purescript-aff for asynchronous processing and purescript-postgresql-client for PureScript wrapper over pg:
Before writing the code, we create the database and the users table using the command-line Postgres client:
$ psql postgres
psql (9.5.4)
Type "help" for help.
postgres=# create database simple_service;
CREATE DATABASE
postgres=# \c simple_service
You are now connected to database "simple_service" as user "abhinav".
simple_service=# create table users (id int primary key, name varchar(100) not null);
CREATE TABLE
simple_service=# \d users
Table "public.users"
Column | Type | Modifiers
--------+------------------------+-----------
id | integer | not null
name | character varying(100) | not null
Indexes:
"users_pkey" PRIMARY KEY, btree (id)
Now we add support for converting a User instance to-and-from an SQL row by adding the following code in the src/SimpleService/Types.purs file:
We can try out the persistence support in the REPL:
$ pulp replPSCi, version 0.11.6Type:? for helpimportPrelude>>importSimpleService.Types>importControl.Monad.Aff (launchAff, liftEff')>importDatabase.PostgreSQLasPG> user =User { id:1, name:"Abhinav" }> databaseConfig = {user:"abhinav", password:"", host:"localhost", port:5432, database:"simple_service", max:10, idleTimeoutMillis:1000}>:paste… void $ launchAff do… pool <- PG.newPool databaseConfig… PG.withConnection pool $ \conn ->do… PG.execute conn (PG.Query"insert into users (id, name) values ($1, $2)") user…unit>importData.Foldable (for_)>importControl.Monad.Eff.Console (logShow)>:paste… void $ launchAff do… pool <- PG.newPool databaseConfig… PG.withConnection pool $ \conn ->do… users ::ArrayUser<- PG.query conn (PG.Query"select id, name from users where id = $1") (PG.Row11)… liftEff' $ void $ for_ users logShow…unit(User { id:1, name:"Abhinav" })
We create the databaseConfig record with the configs needed to connect to the database. Using the record, we create a new Postgres connection pool (PG.newPool) and get a connection from it (PG.withConnection). We call PG.execute with the connection, the SQL insert query for the users table and the User instance, to insert the user into the table. All of this is done inside launchAff which takes care of sequencing the callbacks correctly to make the asynchronous code look synchronous.
Similarly, in the second part, we query the table using PG.query function by calling it with a connection, the SQL select query and the User ID as the query parameter. It returns an Array of users which we log to the console using the logShow function.
We use this experiment to write the persistence related code in the src/SimpleService/Persistence.purs file:
moduleSimpleService.Persistence ( insertUser , findUser , updateUser , deleteUser , listUsers ) whereimportPreludeimportControl.Monad.Aff (Aff)importData.ArrayasArrayimportData.Maybe (Maybe)importDatabase.PostgreSQLasPGimportSimpleService.Types (User(..), UserID)insertUserQuery ::StringinsertUserQuery ="insert into users (id, name) values ($1, $2)"findUserQuery ::StringfindUserQuery ="select id, name from users where id = $1"updateUserQuery ::StringupdateUserQuery ="update users set name = $1 where id = $2"deleteUserQuery ::StringdeleteUserQuery ="delete from users where id = $1"listUsersQuery ::StringlistUsersQuery ="select id, name from users"insertUser ::forall eff.PG.Connection->User->Aff (postgreSQL ::PG.POSTGRESQL| eff) UnitinsertUser conn user = PG.execute conn (PG.Query insertUserQuery) userfindUser ::forall eff.PG.Connection->UserID->Aff (postgreSQL ::PG.POSTGRESQL| eff) (MaybeUser)findUser conn userID =map Array.head $ PG.query conn (PG.Query findUserQuery) (PG.Row1 userID)updateUser ::forall eff.PG.Connection->User->Aff (postgreSQL ::PG.POSTGRESQL| eff) UnitupdateUser conn (User {id, name}) = PG.execute conn (PG.Query updateUserQuery) (PG.Row2 name id)deleteUser ::forall eff.PG.Connection->UserID->Aff (postgreSQL ::PG.POSTGRESQL| eff) UnitdeleteUser conn userID = PG.execute conn (PG.Query deleteUserQuery) (PG.Row1 userID)listUsers ::forall eff.PG.Connection->Aff (postgreSQL ::PG.POSTGRESQL| eff) (ArrayUser)listUsers conn = PG.query conn (PG.Query listUsersQuery) PG.Row0
Serving It
We can now write a simple HTTP API over the persistence layer using Express to provide CRUD functionality for users. Let’s install Express and purescript-express, the PureScript wrapper over it:
Next, we wire up the server routes to the handlers in src/SimpleService/Server.purs:
moduleSimpleService.Server (runServer) whereimportPreludeimportControl.Monad.Aff (runAff)importControl.Monad.Eff (Eff)importControl.Monad.Eff.Class (liftEff)importControl.Monad.Eff.Console (CONSOLE, log, logShow)importDatabase.PostgreSQLasPGimportNode.Express.App (App, get, listenHttp)importNode.Express.Types (EXPRESS)importSimpleService.Handler (getUser)app ::forall eff.PG.Pool->App (postgreSQL ::PG.POSTGRESQL| eff)app pool =do get "/v1/user/:id"$ getUser poolrunServer ::forall eff.Int->PG.PoolConfiguration->Eff ( express ::EXPRESS , postgreSQL ::PG.POSTGRESQL , console ::CONSOLE| eff ) UnitrunServer port databaseConfig = void $ runAff logShow puredo pool <- PG.newPool databaseConfiglet app' = app pool void $ liftEff $ listenHttp app' port \_ ->log$"Server listening on :"<>show port
runServer creates a PostgreSQL connection pool and passes it to the app function which creates the Express application, which in turn, binds it to the handler getUser. Then it launches the HTTP server by calling listenHttp.
Finally, we write the actual getUser handler in src/SimpleService/Handler.purs:
moduleSimpleService.HandlerwhereimportPreludeimportControl.Monad.Aff.Class (liftAff)importData.Foreign.Class (encode)importData.Int (fromString)importData.Maybe (Maybe(..))importDatabase.PostgreSQLasPGimportNode.Express.Handler (Handler)importNode.Express.Request (getRouteParam)importNode.Express.Response (end, sendJson, setStatus)importSimpleService.PersistenceasPgetUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)getUser pool = getRouteParam "id">>=case _ ofNothing-> respond 422 { error:"User ID is required" }Just sUserId ->case fromString sUserId ofNothing-> respond 422 { error:"User ID must be an integer: "<> sUserId }Just userId -> liftAff (PG.withConnection pool $flip P.findUser userId) >>=case _ ofNothing-> respond 404 { error:"User not found with id: "<> sUserId }Just user -> respond 200 (encode user)respond ::forall eff a.Int-> a ->Handler effrespond status body =do setStatus status sendJson bodyrespondNoContent ::forall eff.Int->Handler effrespondNoContent status =do setStatus status end
getUser validates the route parameter for valid user ID, sending error HTTP responses in case of failures. It then calls findUser to find the user and returns appropriate response.
We can test this on the command-line using HTTPie. We run pulp --watch run in one terminal to start the server with file watching, and test it from another terminal:
$ pulp --watch run* Building project in ps-simple-rest-service* Build successful.Server listening on :4000
$ http GET https://localhost:4000/v1/user/1 # should return the user we created earlier
HTTP/1.1 200 OK
Connection: keep-alive
Content-Length: 25
Content-Type: application/json; charset=utf-8
Date: Sun, 10 Sep 2017 14:32:52 GMT
ETag: W/"19-qmtK9XY+WDrqHTgqtFlV+h+NGOY"
X-Powered-By: Express
{
"id": 1,
"name": "Abhinav"
}
$ http GET https://localhost:4000/v1/user/s
HTTP/1.1 422 Unprocessable Entity
Connection: keep-alive
Content-Length: 38
Content-Type: application/json; charset=utf-8
Date: Sun, 10 Sep 2017 14:36:04 GMT
ETag: W/"26-//tvORl1gGDUMwgSaqbEpJhuadI"
X-Powered-By: Express
{
"error": "User ID must be an integer: s"
}
$ http GET https://localhost:4000/v1/user/2
HTTP/1.1 404 Not Found
Connection: keep-alive
Content-Length: 36
Content-Type: application/json; charset=utf-8
Date: Sun, 10 Sep 2017 14:36:11 GMT
ETag: W/"24-IyD5VT4E8/m3kvpwycRBQunI7Uc"
X-Powered-By: Express
{
"error": "User not found with id: 2"
}
Deleting a User
deleteUser handler is similar. We add the route in the app function in the src/SimpleService/Server.purs file:
-- previous codeimportNode.Express.App (App, delete, get, listenHttp)importSimpleService.Handler (deleteUser, getUser)-- previous codeapp ::forall eff.PG.Pool->App (postgreSQL ::PG.POSTGRESQL| eff)app pool =do get "/v1/user/:id"$ getUser pool delete "/v1/user/:id"$ deleteUser pool-- previous code
And we add the handler in the src/SimpleService/Handler.purs file:
deleteUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)deleteUser pool = getRouteParam "id">>=case _ ofNothing-> respond 422 { error:"User ID is required" }Just sUserId ->case fromString sUserId ofNothing-> respond 422 { error:"User ID must be an integer: "<> sUserId }Just userId ->do found <- liftAff $ PG.withConnection pool \conn -> PG.withTransaction conn do P.findUser conn userId >>=case _ ofNothing->pure falseJust _ ->do P.deleteUser conn userIdpure trueif foundthen respondNoContent 204else respond 404 { error:"User not found with id: "<> sUserId }
After the usual validations on the route param, deleteUser tries to find the user by the given user ID and if found, it deletes the user. Both the persistence related functions are run inside a single SQL transaction using PG.withTransaction function. deleteUser return 404 status if the user is not found, else it returns 204 status.
$ http GET https://localhost:4000/v1/user/1
HTTP/1.1 404 Not Found
Connection: keep-alive
Content-Length: 37
Content-Type: application/json; charset=utf-8
Date: Mon, 11 Sep 2017 05:11:03 GMT
ETag: W/"25-Eoc4ZbEF73CyW8EGh6t2jqI8mLU"
X-Powered-By: Express
{
"error": "User not found with id: 1"
}
$ http DELETE https://localhost:4000/v1/user/1
HTTP/1.1 404 Not Found
Connection: keep-alive
Content-Length: 37
Content-Type: application/json; charset=utf-8
Date: Mon, 11 Sep 2017 05:11:05 GMT
ETag: W/"25-Eoc4ZbEF73CyW8EGh6t2jqI8mLU"
X-Powered-By: Express
{
"error": "User not found with id: 1"
}
Creating a User
createUser handler is a bit more involved. First, we add an Express middleware to parse the body of the request as JSON. We use body-parser for this and access it through PureScript FFI. We create a new file src/SimpleService/Middleware/BodyParser.js with the content:
And write a wrapper for it in the file src/SimpleService/Middleware/BodyParser.purs with the content:
moduleSimpleService.Middleware.BodyParserwhereimportPreludeimportData.Function.Uncurried (Fn3)importNode.Express.Types (ExpressM, Response, Request)foreign import jsonBodyParser ::forall e.Fn3RequestResponse (ExpressM e Unit) (ExpressM e Unit)
We also install the body-parser npm dependency:
$ npm install --save body-parser
Next, we change the app function in the src/SimpleService/Server.purs file to add the middleware and the route:
-- previous codeimportNode.Express.App (App, delete, get, listenHttp, post, useExternal)importSimpleService.Handler (createUser, deleteUser, getUser)importSimpleService.Middleware.BodyParser (jsonBodyParser)-- previous codeapp ::forall eff.PG.Pool->App (postgreSQL ::PG.POSTGRESQL| eff)app pool =do useExternal jsonBodyParser get "/v1/user/:id"$ getUser pool delete "/v1/user/:id"$ deleteUser pool post "/v1/users"$ createUser pool
And finally, we write the handler in the src/SimpleService/Handler.purs file:
-- previous codeimportData.Either (Either(..))importData.Foldable (intercalate)importData.Foreign (renderForeignError)importNode.Express.Request (getBody, getRouteParam)importSimpleService.Types-- previous codecreateUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)createUser pool = getBody >>=case _ ofLeft errs -> respond 422 { error: intercalate ", "$map renderForeignError errs}Right u@(User user) ->if user.id<=0then respond 422 { error:"User ID must be positive: "<>show user.id}elseif user.name ==""then respond 422 { error:"User name must not be empty" }elsedo liftAff (PG.withConnection pool $flip P.insertUser u) respondNoContent 201
createUser calls getBody which has type signature forall e a. (Decode a) => HandlerM (express :: EXPRESS | e) (Either MultipleErrors a). It returns either a list of parsing errors or a parsed instance, which in our case is a User. In case of errors, we just return the errors rendered as string with a 422 status. If we get a parsed User instance, we do some validations on it, returning appropriate error messages. If all validations pass, we create the user in the database by calling insertUser from the persistence layer and respond with a status 201.
First try returns a parsing failure because we didn’t provide the id field. Second try is a validation failure because the name was empty. Third try is a success which we confirm by doing a GET request next.
Updating a User
We want to allow a user’s name to be updated through the API, but not the user’s ID. So we add a new type to src/SimpleService/Types.purs to represent a possible change in user’s name:
NullOrUndefined is a wrapper over Maybe with added support for Javascript null and undefined values. We define UserPatch as having a possibly null (or undefined) name field.
Now we can add the corresponding handler in src/SimpleService/Handlers.purs:
-- previous codeimportData.Foreign.NullOrUndefined (unNullOrUndefined)-- previous codeupdateUser ::forall eff.PG.Pool->Handler (postgreSQL ::PG.POSTGRESQL| eff)updateUser pool = getRouteParam "id">>=case _ ofNothing-> respond 422 { error:"User ID is required" }Just sUserId ->case fromString sUserId ofNothing-> respond 422 { error:"User ID must be positive: "<> sUserId }Just userId -> getBody >>=case _ ofLeft errs -> respond 422 { error: intercalate ", "$map renderForeignError errs}Right (UserPatch userPatch) ->case unNullOrUndefined userPatch.name ofNothing-> respondNoContent 204Just userName ->if userName ==""then respond 422 { error:"User name must not be empty" }elsedo savedUser <- liftAff $ PG.withConnection pool \conn -> PG.withTransaction conn do P.findUser conn userId >>=case _ ofNothing->pureNothingJust (User user) ->dolet user' =User (user { name = userName }) P.updateUser conn user'pure$Just user'case savedUser ofNothing-> respond 404 { error:"User not found with id: "<> sUserId }Just user -> respond 200 (encode user)
After checking for a valid user ID as before, we get the decoded request body as a UserPatch instance. If the path does not have the name field or has it as null, there is nothing to do and we respond with a 204 status. If the user’s name is present in the patch, we validate it for non-emptiness. Then, within a database transaction, we try to find the user with the given ID, responding with a 404 status if the user is not found. If the user is found, we update the user’s name in the database, and respond with a 200 status and the saved user encoded as the JSON response body.
Finally, we can add the route to our server’s router in src/SimpleService/Server.purs to make the functionality available:
-- previous codeimportNode.Express.App (App, delete, get, http, listenHttp, post, useExternal)importNode.Express.Types (EXPRESS, Method(..))importSimpleService.Handler (createUser, deleteUser, getUser, updateUser)-- previous codeapp ::forall eff.PG.Pool->App (postgreSQL ::PG.POSTGRESQL| eff)app pool =do useExternal jsonBodyParser get "/v1/user/:id"$ getUser pool delete "/v1/user/:id"$ deleteUser pool post "/v1/users"$ createUser pool patch "/v1/user/:id"$ updateUser poolwhere patch = http (CustomMethod"patch")
That concludes the first part of the two-part tutorial. We learned how to set up a PureScript project, how to access a Postgres database and how to create a JSON REST API over the database. The code till the end of this part can be found in github. In the next part, we’ll learn how to do API validation, application configuration and logging. Discuss this post in the comments.
]]><![CDATA[Gunak — Designing with the Indian Government]]>2017-09-12T00:00:00+00:00http://blog.nilenso.com/blog/2017/09/12/gunak-designing-with-the-indian-governmentWorking with a government body to digitise their offline hospital quality assurance system
What’s the problem?
The NRHM (National Rural Health Mission) is an initiative undertaken by the Government of India to address the health needs of under-served rural areas. The NRHM was initially tasked with addressing the health needs of 18 states that had been identified as having weak public health indicators.
In an effort to better this setup, the Government of India setup the NHSRC (National Health Systems Resource Centre), under the NRHM, to serve as an apex body for technical assistance. The goal of this institution is to improve health outcomes by facilitating governance reform, health systems innovations, and improved information sharing among all stakeholders — at the national, state, district and sub-district levels — through capacity development and convergence models.
One of the areas that the NHSRC works in is the provision of universal healthcare services. Universal access to good quality services — services that are effective, that are safe and satisfying to the patient; services that are patient and community centred, and services that make efficient use of the limited resources available.
The approach for achieving these objectives involves ensuring that every single health facility is scored against pre-defined standards with periodic supportive supervision for ensuring continual improvement.
There are three main components to conducting an assessment,
- Facilities - Assessments themselves, and - Facilitators
Facilitators conduct Assessments for Facilities.
Facilities are hospitals or other healthcare systems that exist at different levels,
National level
State level
District level
District Hospital level
Based on their level, facilities would be eligible for a particular type of assessment.
There are two main types of assessments in the system,
National Quality Assessment System (NQAS): Is a system which has incorporated best practices from the contemporary systems, and contextualised them for meeting the needs of Public Health System in the country
Kayakalp assessment: To complement the government’s ‘Swachh Bharat Abhiyan’ (cleanliness in public spaces campaign), the Ministry of Health & Family welfare, Government of India launched a National Initiative to present awards to public health facilities that demonstrate high levels of cleanliness, hygiene and infection control
Assessments are a set of pre-defined standards against which facilities are scored. Assessments happen periodically throughout the year under supervision to ensure continual improvement.
Facilitators are people with varied experience, who are picked based on the type of assessment. For instance, National level assessments would require facilitators with a certain set of requirements as compared to a State level assessments. For instance, national level facilitators will consist of representatives from the programme divisions (maternal health, child health, family planning, etc.) of the Ministry of Health and Family Welfare, Government of India and National Health Systems Resource Centre.
How does the assessment process work?
The assessment process requires Facilitators to give a Score (of 0, 1 or 2) to a Measurable Element (ME).
Each ME belongs to an Area of Concern (AoC) and an AoC belongs to a Standard.
Standards: These are broad thematic areas with respect to cleanliness & hygiene, and can be termed as the “pillars” of the system.
Area of Concern: Each theme (Standard), has a fixed number of criteria that cover specific attributes.
Measurable Element: Is the lowest and most tangible unit of an assessment. MEs are specific requirements that the facilitators are expected to look for in a facility for ascertaining the extent of compliance and award a score.
Checkpoints: In the NQAS type assessment, MEs are broken down further into Checkpoints. Checkpoints are departmental checklists.
This is how the above-mentioned elements exist in the Assessments,
Assessments for Facilities are done via Checklists, which encapsulate all of the above (Standards, AoCs, MEs and Checkpoints).
How were assessments conducted prior to the app?
Facilitators were handed sheets of paper with all the Standards, AoC and ME on them. Facilitators would traverse back and forth through this list, assign a compliance score to a ME until they were done with all AoC and subsequently with all Standards.
Advantages of the offline system,
Easy and fast scanning of Standards, AoCs and MEs
This medium requires little to no training
Disadvantages of the the offline system,
Hard to keep track of progress. Facilitators have to scan and do this themselves by repeatedly going through the list
Force facilitators to conduct their assessments by the list, rather than what is convenient
Unobliging towards writing comments for scores awarded to MEs
Can’t generate reports immediately
Submitting Assessments as a physical copy and manually syncing the results across the entire district/state/nation
What is Gunak?
Based on the disadvantages mentioned above, Nikhil (senior member of the NHSRC) thought it’d be best to use technology to make the process of conducting and syncing assessments easier. Gunak is the app that aimed at doing this.
Minimum feature list we aimed to launch the app with,
Conduct NQAS and Kayakalp assessments
Motivate facilitators to enter comments for the scores they give
Allow assessments to be conducted offline
Sync assessments once facilitators were in an area with active internet connection
View detailed reports across all Standards, AoCs and MEs for finished assessments
Sync reports of finished assessments for peers/superiors to view/review
The challenges we faced,
Maintain familiarity while transitioning facilitators from an offline to an online system
Translating a multi-tier architecture to mobile
Navigation
Usage: For an assessment to be complete, facilitators have to finish all MEs across all AoCs.
Usage Pattern: Facilitators, physically visit facilities to conduct assessments. The offline medium sometimes forced the facilitators to finish Measurable Elements in a sequential order (as displayed on paper) since it would be easier to keep track of the progress of the assessment.
Notes:
MEs are specific department-wise questions for a facility. Since most facilities aren’t built the same way, following a sequential pattern wasn’t the way to go ahead.
The assessments are usually carried out over a period of 3–5 days.
We wanted to design a system that would be flexible and not dictate facilitator behaviour. A system that would always keep the facilitator aware of where they are and their progress. In addition to this, we had to ensure that readability and usability were the main focus since facilitators moved around a lot while conducting assessments.
The bottom navigation for an ME, allows facilitators to know the progress of the AoC these MEs belong to. It works as a navigation system where facilitators can jump forward to answer an ME and come back to answer another ME.
Search
We wanted to find an equivalent for the ‘flip & find’ function, that facilitators perform on paper, for the app.
Search allows facilitators to find MEs, AoCs and Standards.
Our Search feature isn’t a simple text match. As seen below, it can identify that the word ‘hygiene’, could pertain to a Standard, an AoC or MEs.
Reports
One of the main drawbacks of the offline medium was its inability to generate reports. A facilitator or their superior would spend hours going through an assessment and assign a score for the same.
We took advantage of technology to provide detailed reports based on Departments, AoC and Score, which can be shared as an excel sheet or as an image.
Who did we work with?
This project would not have been possible if it wasn’t for the amazing team at Samanvay. This is our second project with them, you can read about the first one here,
The Gunak app is being rolled out in phases. Its first launch was in August 2017 by the Ministry of Health and Family Welfare, the app has a 4.8* rating on the play store.
Thank you so much for reading this. If you found this interesting, don’t forget to 👏 👏
If you have questions or thoughts about the post and/or would like to reach out to us outside of Medium, send us an email, moshimoshi@nilenso.com